She大数据人工智能教研服务基础设施
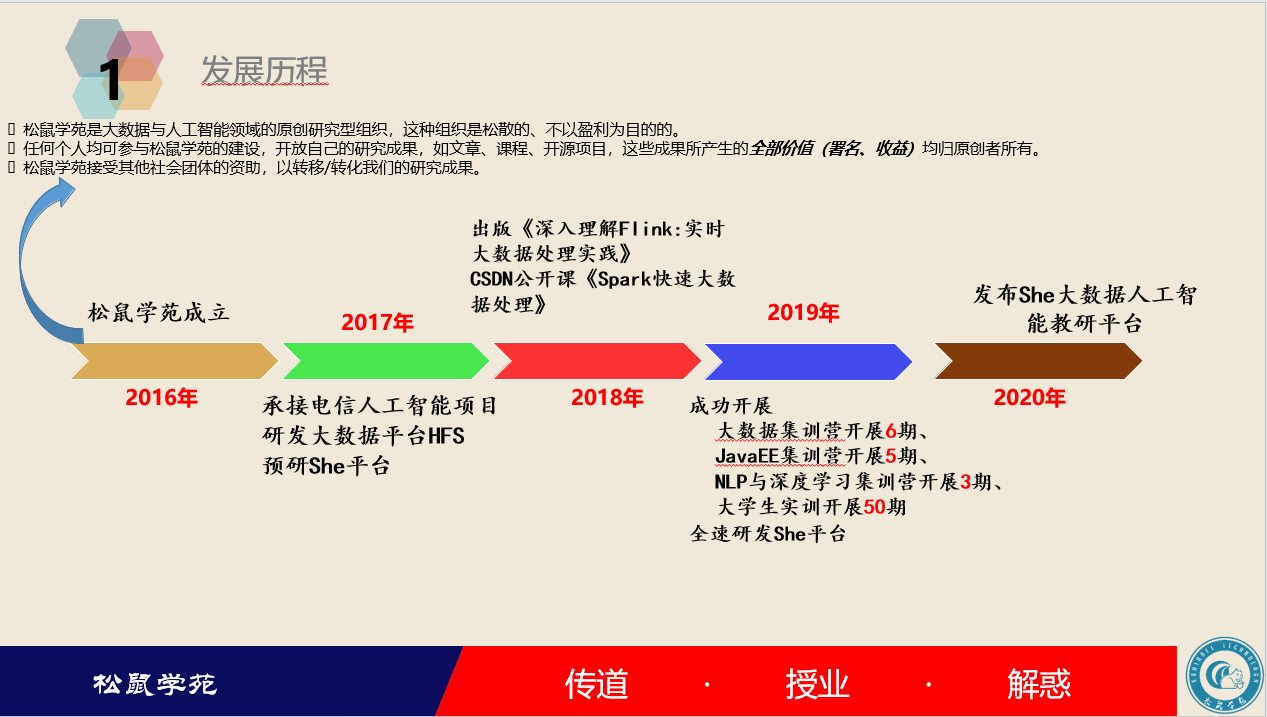
受开源文化的影响和启发,2016年,余海峰先生(下文中松鼠学苑创始人)以个人的名义联合就职于百度、阿里、华为、头条、新浪、58同城等一二线互联网企业以及大型金融机构的资深大数据人工智能资深工程师组建了学术组织松鼠学苑,其目标是推广前沿科技以加快我国的软件科技发展:
松鼠学苑是大数据与人工智能领域的原创研究型组织,这种组织是松散的、不以盈利为目的的。
任何个人均可参与松鼠学苑的建设,开放自己的研究成果,如文章、课程、开源项目,这些成果所产生的全部价值(署名、收益)均归原创者所有。
松鼠学苑接受其他社会团体的资助,以转移/转化研究成果。
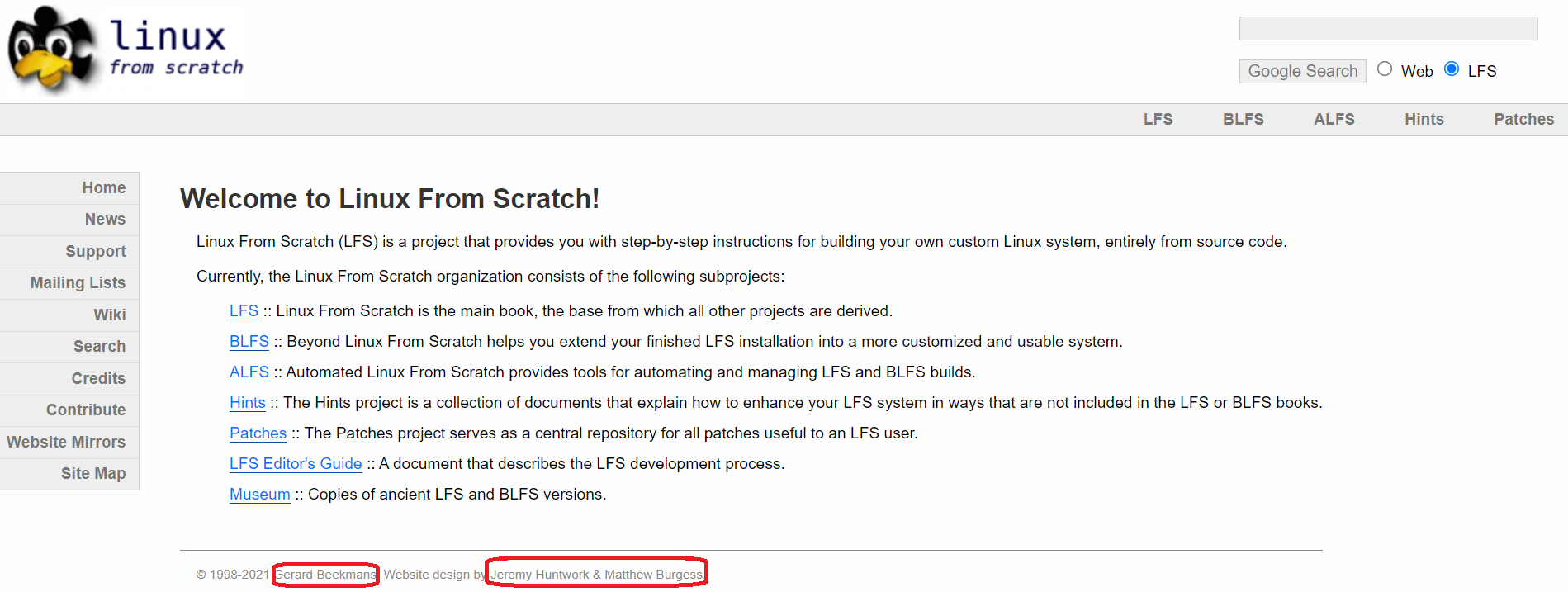
需要特别提及的是,松鼠学苑创始人的第一份工作是在中兴通讯股份有限公司担任板级软件开发工程师,承担Linux操作系统内核定制研发任务,而这份工作所需技能之一来自开源项目LFS(Linux From Scratch),这种以工程师组建的非公司化组织形式的运作模式深深地影响了松鼠学苑及天津精赛科技有限公司的发展,最典型的,公司的很多产品命名方式会带有FS(From Scratch)这个词缀。
以此为契机,松鼠学苑开展了一系列有深度的技术研究工作,如承接基于电信数据的智能语义分析项目、研发HFS(Hadoop From Scratch)平台、开展高端培训与职业教育培训、出版国内第一本关于流处理框架Flink的教材。
在组织大数据人工智能培训班的过程中,松鼠学苑会将近40%的精力投入到实训环境的维护上。当时松鼠学苑给每名学员租用三台云服务器,在学习某个模块(如Hadoop、Tensorflow)之前松鼠学苑会使用Linux脚本将这三台服务器初始化,后来松鼠学苑使用预先编译好的镜像进行初始化以提高效率,但是都会遇到以下问题:
1. 学员的操作会经常出错,而且松鼠学苑的课程中也会经常设置一些”坑”让学员主动出错以加深其对某个知识点的理解,这通常会破坏掉现有的运行环境,这样学员需要重新初始化环境,往往一个30人左右的培训班需要2到3名运维人员承担这个工作;而且即便是不考虑运维人员的投入,这种模式通常会要求学员重复某些已经熟练掌握的操作步骤,这会降低学员的学习效率、同时也会打消学员的继续学习意愿,这是这类强调学习效果的(高端)市场化培训所不能接受的。
2. 学员需要在本地计算机上安装相应软件,如XShell、IDEA、数据库等软件,这通常会面临环境一致性困境,即通常在讲师的环境上可以正常运行的项目却在部分学员的环境中失效,这类问题的排查难度较大,通常会影响课程效果和进度。而且极个别的学员会出现莫名奇妙的、极难复现的问题,特别是做大数据这类软件环境异常复杂的课程时,这类问题出现的概率成倍增加。
3. 在这类课程中,经常会设置本地/远端host、端口等,且经常会使用本地浏览器打开本地或远端服务网页,这通常会遇到远端服务器安全组设置、iptables设置、Selinux设置、以及本地和远端网络地址跳转问题,这类问题对于初学者来说并不是件容易的事;而且如果学员设置了某个特殊的端口还需要松鼠学苑的运维人员介入,这同样会影响学习效率。
经过全面调研,市场上并没有这类问题的成熟解决方案;这期间,微软公司在大力发展Visual Studio Code以替代自家成功占领市场的开发工具Visual Studio XX(如Visual Studio C++),而且有开源团队也在研发网页版的Visual Studio Code,这给解决这类痛点带来了曙光。
于是,2018年,松鼠学苑创始人全职投入到解决这类痛点的工作之中,经过多次迭代和培训试用检验,松鼠学苑创始人终于研发出了对应的软件平台架构,即She(Squirrel technology higher extensible platform)平台架构。这种松耦合的架构设计规避了培训课程平台与底层平台的相互依赖,即底层平台只负责:
1. 基于浏览器的开发环境展现、如网页版的Visual Studio Code,基于浏览器的浏览器,内部服务的一致性暴露,硬件资源(CPU、GPU、内存、磁盘)的抽象与调度管理,物理机的虚拟化实现,docker引擎的重构适配,集群属主机Linux操作系统内核的研发,基于浏览器的远程Shell等一系列基础架构组件。
2. 语言环境(Language Server)的架构,即构造一套统一的语言环境,详细介绍见附件(附件1、Devfile和Workspace的定义)。
3. 实现由Devfile定义的课程环境架构(详见2.2 She平台架构优势)。
那么,为大数据、人工智能等课程专门建设相应课程实训平台,并将这类平台构架在She平台底层架构之上,成为这种松耦合架构的成功之处。
此外,通常不特殊指代的情况下,这里提及的She平台是指集成了所有学科实训平台的教研基础设施,如大数据教研平台、人工智能教研平台。
为了方便开展校企合作业务,在天津注册成立天津精赛科技有限公司,由余海峰先生担任公司负责人,此后,松鼠学苑这个品牌由天津精赛科技有限公司运营,并先后成立北京研发中心、天津运营中心。
1. 承接了基于电信数据的智能语义分析项目
企业的业务平台通常会以短信的形式给其用户发送业务办理进度的通知,业务量大的平台会选择购买短信流量以节约成本。在国内,短信流量服务市场格局基本稳定,因此大量这类短信集中在少数几个头部短信流量服务供应商手中;此外,原始短信主要集中在移动和联通等运营商手中。
这类短信有很重要的商业价值,特别是在金融行业,如线上纯信用借贷平台发送的各类短信(申请、审批、还款、逾期催收),能够真实的反映受信方的信用状况,是个人授信模型训练、验证的基础数据,其中,获取短信的语义是建模的关键。但是,由于这类数据文本较短,很难使用基于篇章的NLP技术去建模做语义分析。松鼠学苑承接了合作方(短信流量服务供应商)的智能语义分析项目,为此松鼠学苑主要开展两项技术攻关,
构建大数据平台,以分布式计算解决每天增量为PB级的数据分析任务。
训练深度学习NLP模型用于语义理解与分类,并根据语义输出结构化标注构建文本的特征,并实时更新信息主体(信贷场景下的受信方)画像。
2. 研发HFS(Hadoop From Scratch)平台
基于电信数据的智能语义分析项目的训练与验证并不需要实时大数据处理技术,但是这个模型部署在生产环境中需要实时更新自己的特征值,这需要实时大数据处理框架的支持,而当时Flink框架比较新,已有的大数据平台并没有很好的集成这个框架,所以需要自己研发对应的大数据平台。
此外,由于客户提供的生产环境机房条件并不能保证已有的通用大数据平台进行高速大规模数据处理,这需要花费巨大的精力进行裁剪以适配客户的机房条件,而这种裁剪的工作量是巨大的、且裁剪工作存在很大的失败风险,所以采用从源码编译的方式重新搭建一套大数据平台,这便是研发HFS平台的背景。
HFS平台的典型特征如下,

3. 开展高端培训
考虑到松鼠学苑的非公司化组织形式最有利于开展培训类业务、特别是高端培训业务,经过市场调研,松鼠学苑开展了以下培训班:
大数据集训营
JavaEE集训营
NLP与深度学习集训营
企培和大学生就业实训
截至2020年底,松鼠学苑共开展大数据集训营52期、 JavaEE集训营35期、NLP与深度学习集训营22期、高端企业培训12场。这些经验是松鼠学苑能够从容从事计算类学科建设的核心资产,也是松鼠学苑能够和体量庞大企业竞争的底气。
4. 课程体系建设
为了培养全面掌握大数据基础设施架构原理以及基础设施组成框架间关联关系的中高端人才、培养大数据实用型人才,松鼠学苑建设了大数据人工智能课程体系。
大数据方向课程体系建设如下,
人工智能课程体系建设如下,
5. 出版实训教材与课程
(1)、出版国内第一本Flink流处理技术实训类教材《深入理解Flink:实时大数据处理实践》。这本教材重点讲述流处理技术架构原理与Flink实现方法、以及实时机器学习的架构与实现,为大数据集训营提供强有力的教材支撑。
此外,本教材为”十三五”国家重点出版物出版规划项目的大数据丛书,全面阐述了大数据的理论特征和实践特征,为从事大数据领域研究和高校教学提供了参考书籍,带动了国内大数据基础理论的研究热潮,纠正了大数据就是数据买卖的功利化认知。
(2)、研发教案《NLP技术精要》,以剖析BERT、GPT-3、XLNet实现代码为核心内容,讲述NLP的核心思想、特别是注意力机制的核心思想,为NLP技术的推广做出了巨大贡献。
(3)、教案《大数据框架全栈》详细讲述大数据生态中主流的数据处理框架的搭建与应用,成为开展大数据专业校企合作的核心资产,松鼠学苑会根据学校生源情况选择部分章节、并在这些章节的基础上定制出适用课程。
(4)、此外,CSDN上发布的大数据公课程《Spark快速大数据处理》,深受学员好评,并成为众多高校开展大数据教学的参考方案。
(5)、由于篇幅较长,关于大学生实训类课程,请参考《松鼠学苑She大数据人工智能教研平台宣传册》。
1. 开展师资培训
师资培训项目于2021年初启动,截至2021年11月份,松鼠学苑共开展线下师资培训2期、线上师资培训10期。
师资培训以项目及其实操为核心,为高校培养大数据人工智能学科教师:
项目1:PB级数据处理
项目背景与研究内容:C、Shell、Python、Scala的大规模数据处理程序的执行效率对比分析,引出大规模数据处理方法论变革的软硬件动因,并反向实证大数据变革的技术驱动;大数据底层编程语言MapReduce的设计思想;以需求为导向阐述大数据集群结构与大数据生态体系。
项目2:复杂社会网络的研究
项目概要:大数据存储与大数据处理技术的推动,人类个体的选择愈发依赖于数据所揭示的成功道路的指引。从事科研,借助于论文大数据,通过相互之间的引用关系网络,能够透析研究方向和进入时间点与成功之间的内在关系;借助于六度分隔理论,可以理性认知”世界真小”、尚未成功并不是因为缺少关系网;通过股票市场指标的变化,可以建模反推个体的决策偏好,降低盲从的代价。
以Flink/Hive/Hadoop集群作为数据处理的工具,以计算图作为程序设计理论,以实际计算的结果印证复杂社会网络的研究结论,而不是一系列美妙的心灵鸡汤。
项目3:基于深度网络的图像识别
项目概要:谈起人工智能,广场舞大妈都能说出一系列人工智能对社会的推动案例、并能谆谆教导年轻一代好好学习科学知识;但人工智能的原理,特别是深度神经网络的原理是不是那么高不可攀,很多人未必能够厘清。
以TensorFlow为深度神经网络训练工具,以各类可视化图像为基础,抽丝剥茧,感性认知人工智能,并基于此做出对人工智能发展方向的准确判断。
2. 开展大学生实训
共开展了大学生实训350期:
(1)、大学生零基础就业培训班。
(2)、在天津,与中国天津职业技能公共实训中心合作,松鼠学苑承担了天津市高校大四年级学生的计算机类学科实训任务。
3. 研发落地She(Squirrel technology higher extensible platform)平台。
She平台包括两个版本,C端版本部署在松鼠学苑的公有云上、面向相关领域从业者提供学习培训任务,高校版本通常部署在高校机房、为大中专院校提供学科教研实训,其中截至2021年11月C端版本累计67653名付费用户,23260名大学生实训用户。
其他情况后面会有专门章节介绍,这里不再赘述。
为了阐述计算机类学科教学实训的痛点,这里以大数据为例总结分析。
大数据教研与开发,集群环境搭建是第一步,也是最困难的一步,其困难程度之高往往导致学习者过早地放弃进入这个技术领域。首先,搭建一个包括3节点虚拟机的最小集群,至少需要12G+内存,这要求个人本地计算机至少安装16G物理内存,这还没有考虑CPU的情况。其次,即便是具备了这个基础条件,大数据的学习过程需要一个不短的周期,而要保持这个集群一直运行也不现实,关闭本地计算机通常会导致集群不能正常地再次启动;有谁能随随便便成功呢,爱迪生发明个灯泡还用了7000次实验呢,学习任何技艺都会出现反复实验,但,从一种配置回退到另一种配置,这也是从业者的噩梦。从教学角度上看,错误或故障教学是重要的教学方法。
因此,部分高校选择单节点虚拟机或虚拟桌面的模式,将环境维护的任务抛给学生,解决的较好的学校可能选择定制化一部分预装镜像,这无疑都会增加学生学习的门槛,加大教师授课和课程研发的难度,特别的、当这类学科发展太快而经常需要更新课程内容时。此外,还有部分高校,特别是985、211高校,只注重理论教学不注重实践教学,学生学得一知半解;但这类学科特点是理论和工程实践都很重要、甚至于动手能力往往比理论更重要。
经过长期的企培和校企合作实践,松鼠学苑总结出计算机类学科教研普遍痛点:
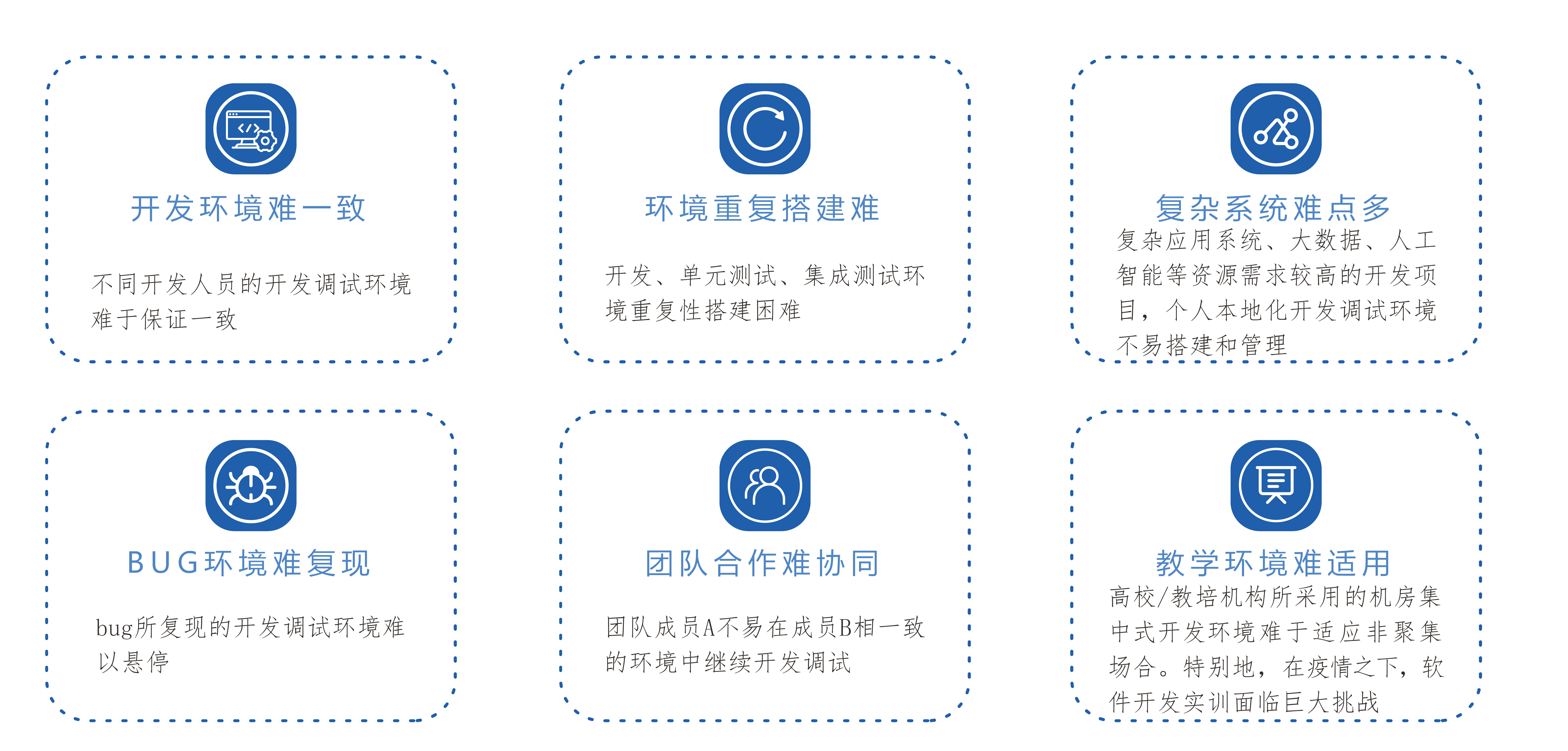
其中,在这类学科教学中经常会采用分组实训模式,即将班级拆分成多个小组,小组成员共同完成一个教学任务,这和企业研发和高校科研的情景类似,因此团队合作也是教学任务之一,团队合作难协同就是这种场景下的痛点之一。
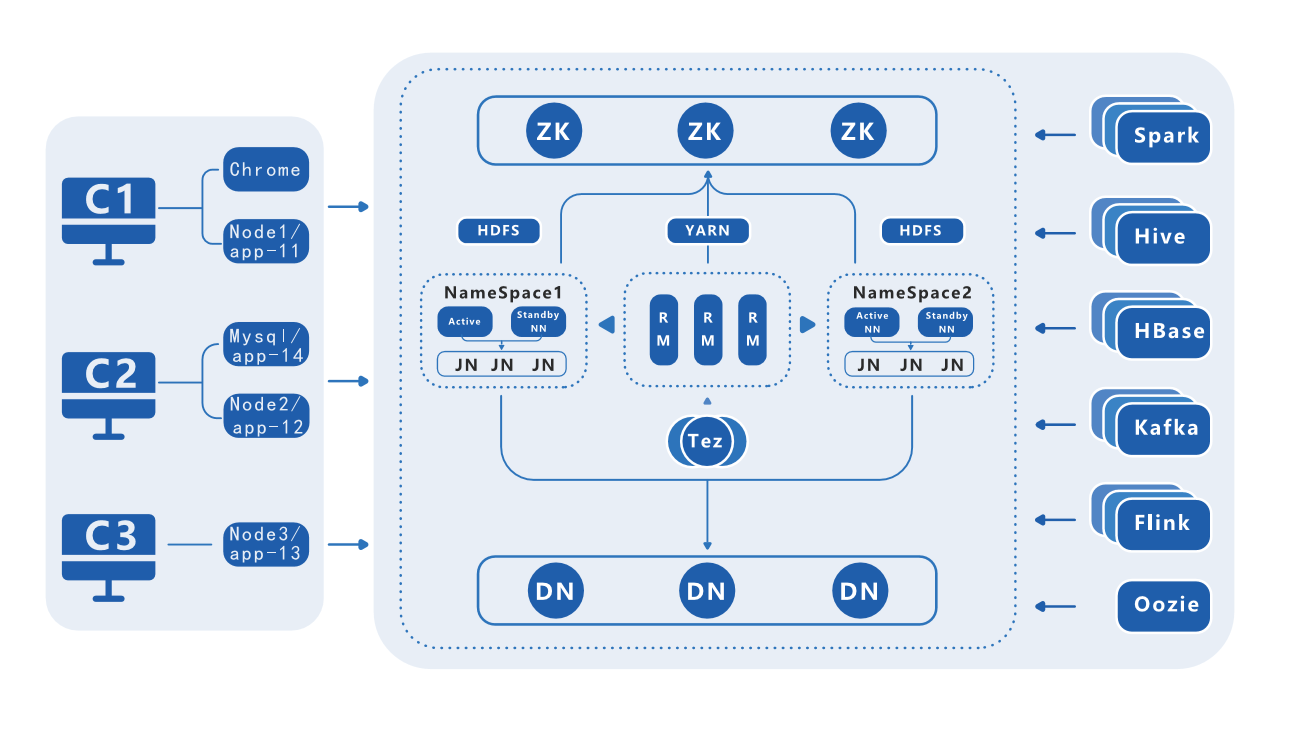
为了解决这些问题,经过3年研发打磨,松鼠学苑开发出HFS平台以解决大数据教研困难,并将HFS(Hadoop From Scratch)集成进She(Squirrel technology higher extensible)平台之中:She提供3个Workspace,并由这3个Workspace组成大数据集群,这3个Workspace分别以hadoopc1、hadoopc2、 hadoopc3命名,而不管这3个Workspace镜像所对应的是哪个阶段。举例,创建一个HBase阶段的集群,那么这3个Workspace以hadoop为前缀命名,而其所属的阶段(Stack)则以HBaseC为前缀命名,所以一个账号只能搭建一套这样集群。其中hadoopc1包括两个容器,分别为远端浏览器Chrome、节点Node1,其中远端浏览器用于访问集群内部资源,因为这些资源并没有映射到外网;hadoopc2包括两个容器,分别为MySQL、节点Node2;hadoopc3则只包括一个容器,即节点Node3。
1)虚拟机技术
在CSDN等课程平台上的很多大数据相关课程使用这种技术,不少高校也采用这种技术。
这种技术主要的弊端在于:1、保存、创建虚拟机困难。2、每一个阶段有一个虚拟机镜像,需要几十个G,耗费资源非常大,学生不易管理。3、管理集群状态与一致性困难。
因此,这种解决方案不能给学生实战平台,只是在理论层面上的一种灌输,学生无法通过有效的实操搞清楚大数据基础设施的一系列框架的原理以及这些框架的关联关系,很难培养出中高端人才。
这种技术的优势:成本低,几乎没有软硬件的投入。
2)虚拟桌面解决方案
这种解决方案需要学生自己去搭建,是单机版、模拟版的,效果达不到,只能最简单的模拟,不能做集群的模拟,与工业级应用之间存在差距,影响学生就业竞争力。此外,这种解决方案传输的是视频流,带宽要求高。
这种技术的优势:已有成熟的云桌面产品。
3)云原生解决方案
弊端:学生需要操作服务厂商提供的云服务管理组件、如端口与权限,这极大的增加了学习门槛而不是将专业实训聚焦在课程本身上;而且,由于大数据人工智能系统中组件与服务众多,往往需要更为”本地”的环境,如localhost、hostname,云原生的解决方案很难满足这种情况。
这种解决方案通常是给从业人员做测试环境用的,大厂商为了快速占领市场简单粗暴的将其铺展到高校。
这种技术的优势:公有云唾手可得。
4)大集群、多租户的工业集群
弊端:不能修改集群的配置信息,做不了大数据人工智能的原理教学;共享式的集群环境,操作带有差异,如删除hdfs中某个文件的含义是删除每个学生自己定义的某个目录下的某个文件、而独立集群则保持了教材上操作指令对所有学生的一致性。
这种技术的优势:有IT支撑业务的企业基本会采用这类成熟解决方案,因此这种解决方案零研发投入;现在基本上没有高校引入这种方案。
She平台以虚拟化技术为核心,打造全新的docker引擎和k8s集群、定制优化Linux操作系统内核,为每名用户(学生)提供一套分步骤、分阶段的、一致的、隔离的操作环境,解决计算机类(不仅仅是计算机类、如BIM建筑信息类)学科教学实训痛点,主要策略如下:
1. 状态悬停:开发环境具有悬停功能,所有启动的软件工具均运行在云端后台,关闭开发界面后,开发环境仍保持最后一次更改的状态;
2. 云端部署:基于虚拟化/云计算技术,提供一套仅需浏览器就能开展软件开发调试工作的云IDE,规避了学生本地环境搭建的复杂性;
3. 自动保存:代码实时保存在git/svn服务器中,关闭开发界面再次进入之后代码仍保持最后一次更改的 状态;
4. 一致性保障:同一开发环境由对应devfile所定义,并在启动时由k8s集群配置相应资源。由于资源均来自预先制作的docker镜像,这保证同一开发环境可无限数量且一致的复制;
5. 用户环境隔离:每个账号可启动多个相同/不同的开发环境实例,所有账号间以及(相同)开发环境实例间是隔离的,以避免相互影响;描述bug更加容易:只需将账号给对方即可利用开发环境悬停功能展现bug所产生的运行上下文;
6.软件平台支持拖拽式,方便操作,可以随时创建随时删除,创建和删除的是逻辑的计算机集群。
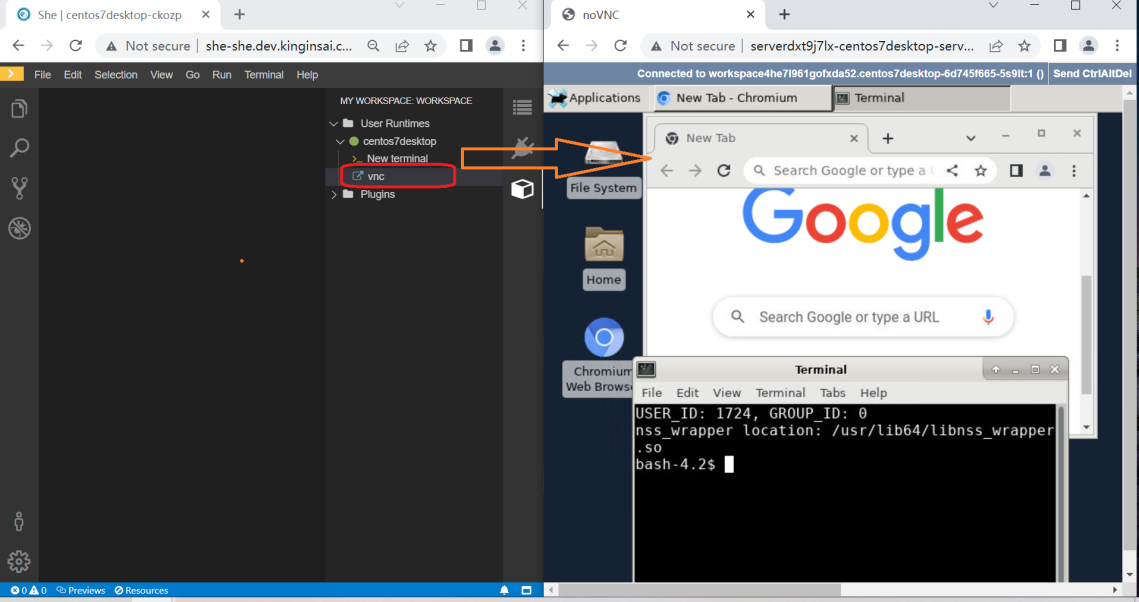
用户登陆后,在主界面中可以选择目标课程平台环境,如大数据集群裸Linux集群Centos7C1、Centos7C2、Centos7C3,

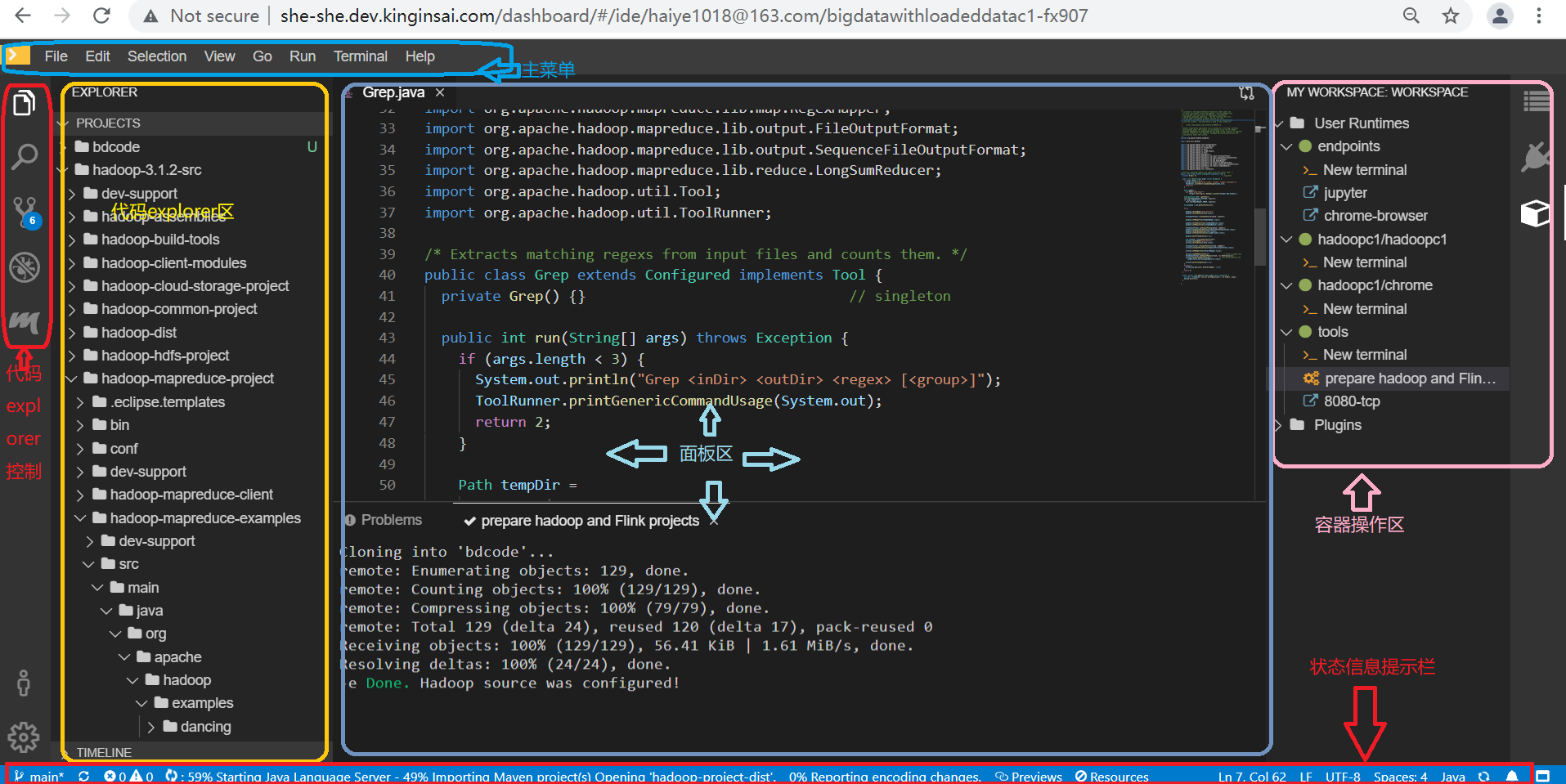
于是,一套开发环境便创建成功。典型的,She平台的课程环境界面包括5个区域(某些课程环境并不一定全部包括这些区域):主菜单、代码explorer控制菜单、代码explorer区、面板区、容器操作区,这些区域设计能够满足所有教研实训需求。
从”Getting Started”选取一个模板、点击”Created & Open”创建一个Workspace,而模板则是由一个文件定义的、这类文件称为devfile、即devfile定义模板而Workspace是模板的一个实现。
每个课程由若干个Workspace组成,如集群版的大数据课程至少包括3个Workspace。
一个Workspace则由多个容器组成,每个容器可以看成一台物理计算机;这些容器又分为两类,分别为:User Runtimes和Plugins,大部分情况下操作User Runtimes中的容器。
每个容器通常包含3类操作元素:终端(>_ New Terminal)、预设命令、端口。
终端只有一个菜单项,点击此菜单(>_ New Terminal)可以创建一个终端,对于Linux类的容器来说,在面板区创建一个命令行操作界面。可以调整命令行界面的高度,也可以占有全部面板区域、即最大化。此外,可以通过多次点击菜单(>_ New Terminal)创建多个终端。

预设命令可以有多条,每条可以认为是一个shell脚本,用户完成某个任务,如下载指定资源到当前容器中。当鼠标停留在对应预设命令菜单上时,此命令的shell脚本内容会显示出来。
端口可以有多个,点击每个端口,会在浏览器上打开对应网页;但是这个端口并不一定被应用程序所绑定,需要事先设定后才能正常打开对应网页。
She平台是构建在docker/k8s之上、用于软件开发调试的松耦合平台、平台本身是架构在大数据集群之上的分布式系统,共包括三层:
(1)、资源管理层:管理服务端的核心资源,共分为三部分:计算资源(CPU、GPU)、内存资源、存储资源;k8s调度资源;周边组件资源。
(2)、She核心调度层:管理并调度用户的课程创建删除操作请求到对应资源承接端,提供统一功能模式的(计算机)语言环境、编辑器、操作端子。
(3)、应用层:本层集合了所有课程环境,以解耦底层功能组件与课程环境:
1、Devfile是开展某层项软件类开发任务所需要环境的定义,那么将这个草稿建设起来的就是Workspace,即Workspace是物理的,而Devfile是逻辑的、是静态的。Workspace包括了物理运行的各容器或物理机实体、端口、命名等一干看得见摸得着的资源,所以Devfile定义了某个实训任务的资源需求情况,如CPU、GPU、Memory、Disk等,而运行中的Workspace则实际占有了这些资源,因此,从这个意义上看,具体的实训任务决定了She平台的硬件配置需求。
2、Devfile是She平台的预置环境,即其对应的Workspace中已经安装了一系列版本号确定的工具,这些工具集的选择是根据开发任务的通用需求而定的,是通用的;但可以根据需要卸载、升级、安装相应工具。
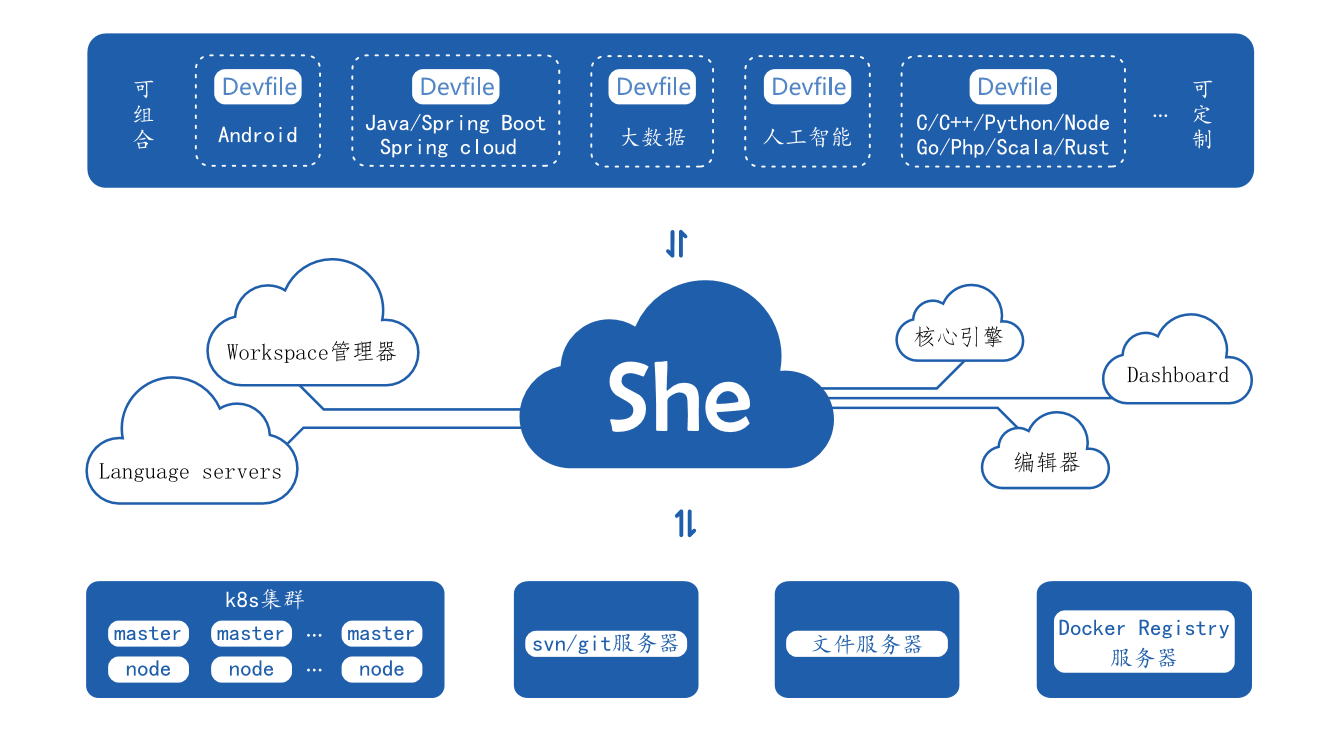
这种架构的优势如下,
1.这种松耦合的架构可解决课程持续迭代和平台基础功能升级之间的依赖,并且可以随时扩容计算资源以满足学生数量的突发增长;概括起来”教师不需要关注学生如何操控实训环境、当在校学生人数增长时学校只需增加相应数量的计算节点服务器即可”。
2.可支撑校级、国家级实验室服务能力。理论上,She平台的底层集群可以水平扩展到10万节点的规模,而每个节点的峰值可服务于50名学生(低资源消耗型教学实训,如Java开发实训则这个数值为200),没有访问和服务能力瓶颈。
这里需要特别说明同期服务能力的含义。假定实验室有600个实训机位,那么具备5000名学生同期开展教研实训能力的含义是教研基础设施应具备5000个账号所申请的Workspace同时运行的能力,尽管可能在某个时间点上只有600个账号同时登陆系统操控这些Workspace;从教学上看,一门课程通常需要经历一个周期,如一个学期,这里的同期就是同一个教学周期。
3.易用性优势:这套平台最初是为松鼠学苑开展培训而研发的云端平台,运维团队可简洁高效地维护这个平台也是设计的目标之一。以用户获取资源使用权限为例说明。平台注册并登陆系统页面是没有限制的,但是创建Workspace以获取可使用资源却需要授权。授权的模式有多种,用户可以通过微信付费购买的方式获取,也可以由平台的运维人员在后台管理页面添加获取,还可以由用户端发起免费使用申请、由平台的运维人员审核的方式获取,这几种模式均对应着不同的应用场景,满足每一个场景下的用户的使用习惯。最后一种模式参见附件2、申请免费授权使用操作流程。
4.全英文界面,引导学生快速融入:涉及到大数据、人工智能、软件开发领域的词语大都来源于欧美以及以英语为官方语言的开源社区,如果生硬地将这些业内从业者所熟悉的词汇和表达转换成中文,则一者这种转换很难用较短的词汇表达的那么清晰(因为页面上用词都是短词汇)、二者也无法让松鼠学苑平台的学员用户快速融入这个软科学领域。
5.可无缝的集成其他支撑系统:
(1)、在线课程平台:为了给学生更好的学习体验,松鼠学苑采用了电子书的形式展现课程,将文字和视频融合在一起。
(2)、Git仓库:课程中涉及到的资源均存储在Git仓库中,学生使用git clone命令便可以下载相关资源;She平台任一容器均内置git命令。
(3)、可定制的教学平台:松鼠学苑采用开源的moodle作为教学平台内核,可根据学校的要求定制;带Android和iOS版本App,教学平台的主要功能如下,
1).使用基础:包括课程申请、课程资源、课程活动、文件管理;课程设置、日志与报表、备份恢复。
2).过程管理:包括小组分组、班级管理;课程进度管理;日历/日程管理;考勤管理。
3).作业管理:括作业布置、递交、评分、批改反馈。
4).协作学习与评价:包括讨论区的使用(新建讨论区、添加新话题、回复话题)、互动评价的使用(包括新建评价,评价各阶段管理)。
5).音视频资源应用:包括新建Videofile、编辑Videofile、视频编辑工具、RSS订阅。
6).课程测验:包括题库管理、测验管理。
7).成绩管理:包括成绩设置、学生成绩报表管理、成绩计算公式使用、成绩类别管理、成绩项管理、成绩导入/导出。
8).其他功能:通用数据库、图片库、词汇表、固化教程、即时聊天、投票、URL、图书等资源与活动。
(4)、http文件服务器平台:提供全局文件访问功能,支撑wget方式下载。
6.She平台是教研基础设施:She平台内置大数据、人工智能等学科教研平台,这些学科平台是融合一起的,而不是分离的大数据教研平台、人工智能教研平台、网络空间安全教研平台…。
7.内置虚拟桌面模式:考虑到虚拟桌面模式的门槛比较低,She平台内置了这种模式,但借助于She平台的纯浏览器访问特征,She平台的虚拟桌面模式更加易用。
8.软硬件的松耦合:She平台不依赖于特定的硬件性能,She平台提供的优化Linux内核可以运行在主流的硬件平台上,平台本身消耗的资源非常小;我们会根据课程设置与同期开展教学实训学生人数等情况配备资源,当校方的预算不足时,我们会裁剪资源消耗较大的实训项目以适配校方的硬件条件,所以我们会常常询问校方的预算以配备相应规模的硬件条件。
9.强大的理论研究团队支撑:得益于松鼠学苑的机制、以及松鼠学苑创始人在大数据人工智能方向的研究与工程实践,She平台的软件架构设计是在深入翔实理论分析的基础上进行的,这种集基础理论研究和先进软件架构设计于一体的设计确保She平台能够适应大数据人工智能的快发发展。
10.科技公司的基因:松鼠学苑以领域内有影响力的专家学者为核心组建,我们提供的是有深度的项目研发与高端培训服务,这是我们与市场上以培训为主营业务的培训学校的主要区别,这也是我们能够越过虚拟桌面类产品研发She大数据人工智能教研服务基础设施的重要资产。这种科技公司的基因造就She平台的优秀架构,反过来,这种优秀架构又增强了科技公司基因。

目前主流的云终端解决方案分为两类,一类是将算力集中在云端的传统云终端,典型代表是 VDI;一类是将算力分布在终端的新型云终端,典型代表是 IDV 和 TCI。
VDI是基于早期的RDP协议和瘦客户机逐步演变而来的,也是国外VMware等国外虚拟化厂家长期鼓吹的模式。VDI旨在为智能分布式计算带来出色的响应能力和定制化的用户体验,并通过基于服务器的模式提供管理和安全优势。它能够为整个桌面映像提供集中化的管理,但这一模式也存在着其固有的问题。主要表现为:因其利用硬件仿真及瘦协议,使得视频、Adobe Flash、IP 语音(VoIP)以及其它计算或图形密集型应用不适用于该模式,而且VDI 需要持久的网络连接,因此不适于要求离线移动性的场合。此外,其基于服务器的模式对服务器的配置有极高的要求,这些问题的存在不能不让众多的用户重新考虑部署VDI的实际意义及成本。 从实际应用方面来分析,VDI模式还存在诸多需要解决的问题,而与之相关的虚拟化桌面,如远程托管桌面、远程虚拟应用程序、远程托管专用虚拟桌面、本地虚拟应用程序及本地虚拟操作系统等虚拟化桌面也都存在着各种问题;另外还有对终端硬件的支持问题、对网络及服务器硬件过度依赖的问题、以及数据安全性问题等。
VDI桌面虚拟化的优势在于运算集中在服务器端,因此在以下两种环境中特别合适:
1、在极小的广域网带宽环境下,例如低于500Kbs的线路下,可以采用VMware等VDI产品进行部署,用户可以使用平板电脑或者手机接入,访问自己的桌面环境,实现随时随地办公;
2、在新建的全千兆网络环境下,同时业务应用比较简单的环境中,用户部署VDI桌面虚拟化后可以购买100元左右的云终端作为客户机,大大减少客户机的硬件投入,拉平在服务器上的硬件投入,使得总投资更加合理。
She平台内容云终端使用VDI模式,但在此基础上提供基于web的访问模式,即用户只需打开本地浏览器便可以操控远端的虚拟桌面,而且借助于She平台提供的基础架构,用户可以随时删除、随时创建(多个独立)虚拟桌面。但相比于She平台的非桌面解决方案,虚拟桌面解决方案需要更大的带宽,更适用于本地部署的是由云模式。
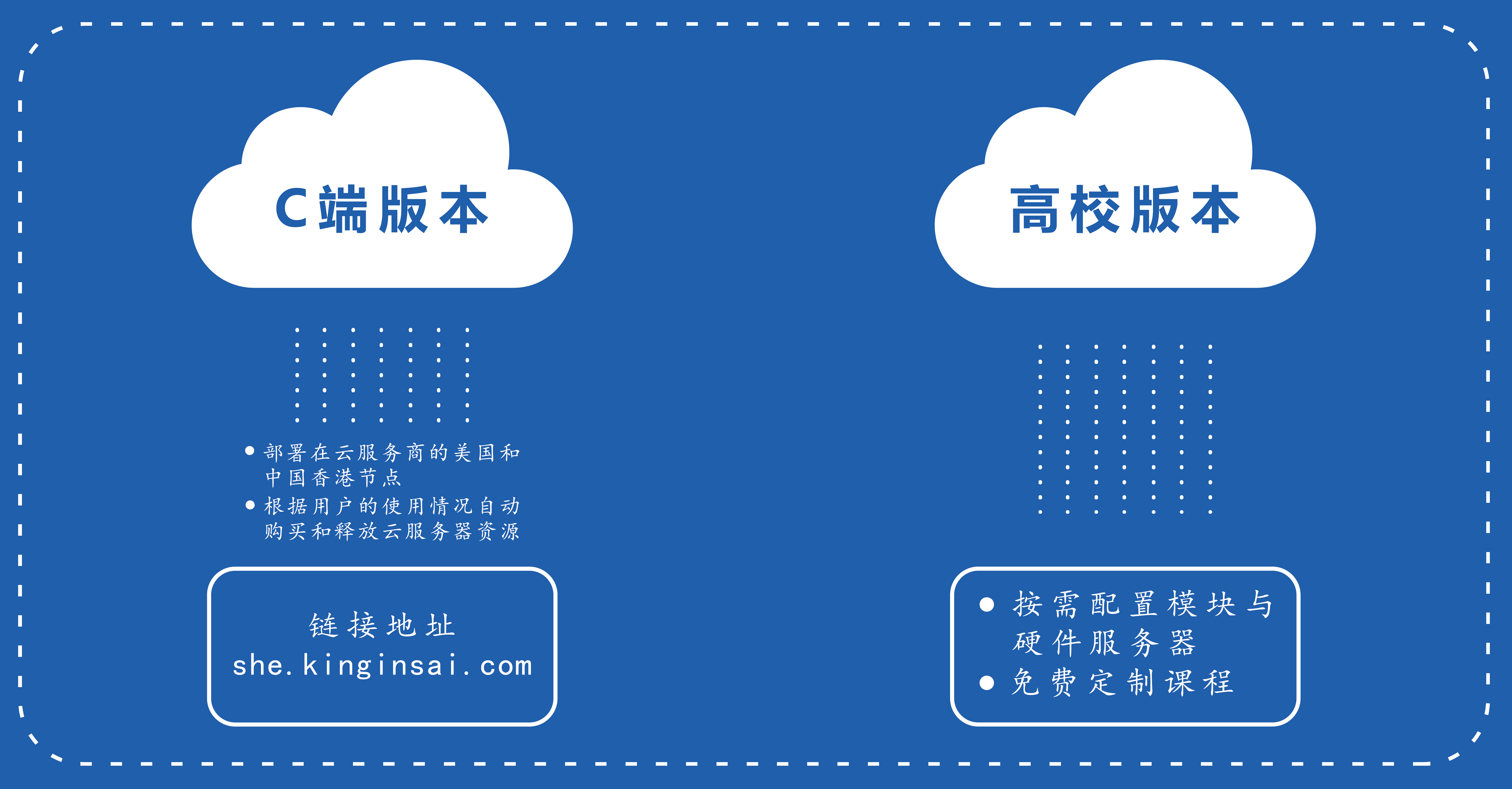
She平台包括两个版本:C端版和高校版,其中C端版本部署在松鼠学苑的公有云上、面向相关领域从业者提供大数据/人工智能等计算机科学学习晋升服务,而高校版则为大中专院校提供大数据/人工智能等计算机专业教研服务。
She的C端版本登录地址为 http://she.kinginsai.com,只需要邮箱即可注册账户,可以查看我们的课程环境;可以关注我们的公众号:松鼠学苑、或扫描下面二维码,

获取我们的She平台手册和部分公开课程资源。
大数据学习包括两个方向:
首先,作为基础设施,学员需要领悟架构这个基础设施的基本原理以及选择这种架构模式的深层次逻辑,这就是学习构建这个基础设施的一系列框架以及这些框架的关联关系。
其次,产业界的最终目标是基础这个基础设施开发上层应用,即大数据的应用部分,这对应用于商业智能分析、机器学习及其相关算法的学习。由于数据特点及应用领域的差异,这个部分通常会有较大差异。在She教研生态体系中,松鼠学苑基于AFS(AI From Scratch)平台开展大数据应用部分培训;基于BiVisual平台开展大数据商业智能分析。
本着为社会培养产业急需的大数据人才、解决新兴科技人才短缺与产业人才分布不合理问题、服务于国家科技振兴大局的宗旨,发挥校企共建的互补优势,松鼠学苑在大数据学科建设方面具备以下优势:
1.全生态大数据基础设施。大数据教学中,松鼠学苑提供全系列、分步骤镜像,学生能从任一成功阶段继续开展后续的学习任务,从裸Linux到Zookeeper、Hadoop、Tez、Hive、Spark、Oozie、Hbase,到Kafka、Redis、Sqoop、Flume、Flink、Hudi,All in One的Jupyter,最新版本的TersorFlow,集成Python、Java、Scala、R、Julia等大数据处理语言。
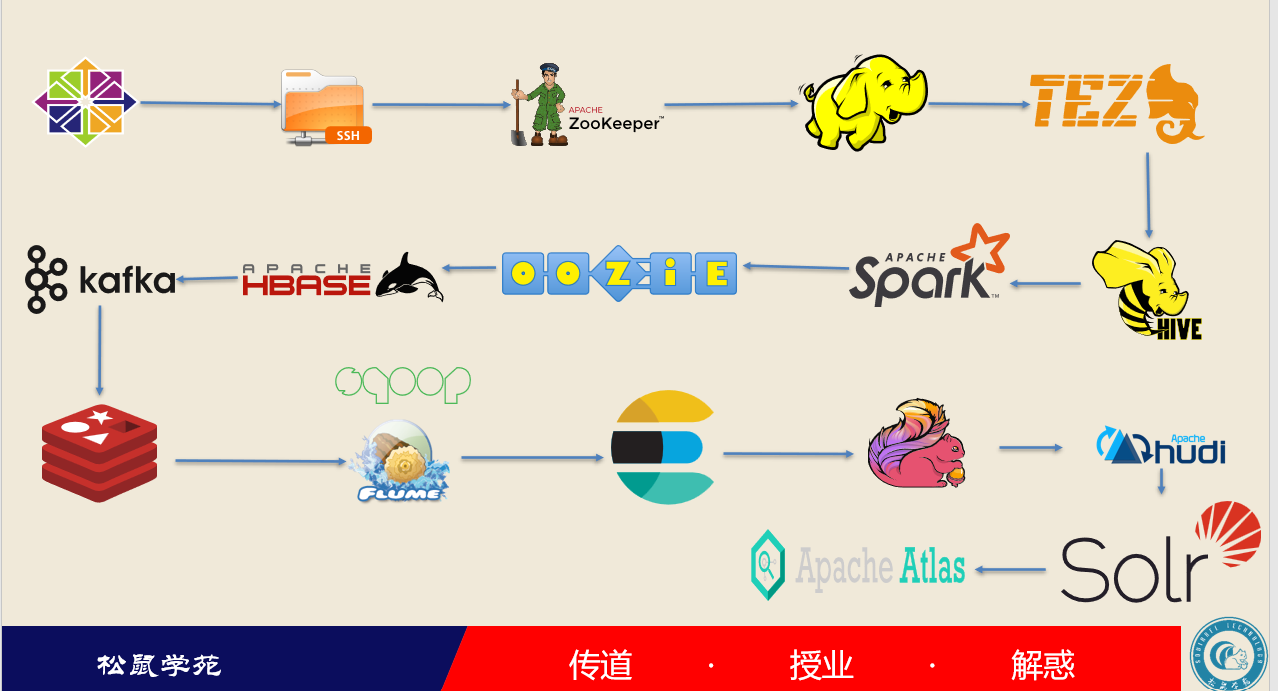
2.每名学生一套独立三节点HA集群。可以随时创建随时删除集群,学生环境间相互隔离,所有学生端的资源命名均相同,如hosts、端口等,降低了学习门槛、提升了学生的学习效率、提升了学生的企业适应能力。
3. 丰富的教学资源与教学经验:作为最早从事大数据培训的机构,松鼠学苑积累了丰富的大数据方向面向工程师的企培、面向架构师的高端企培、师资培训、大学生实训经验,掌握了不同学业水平的受众的启发式教学技巧。
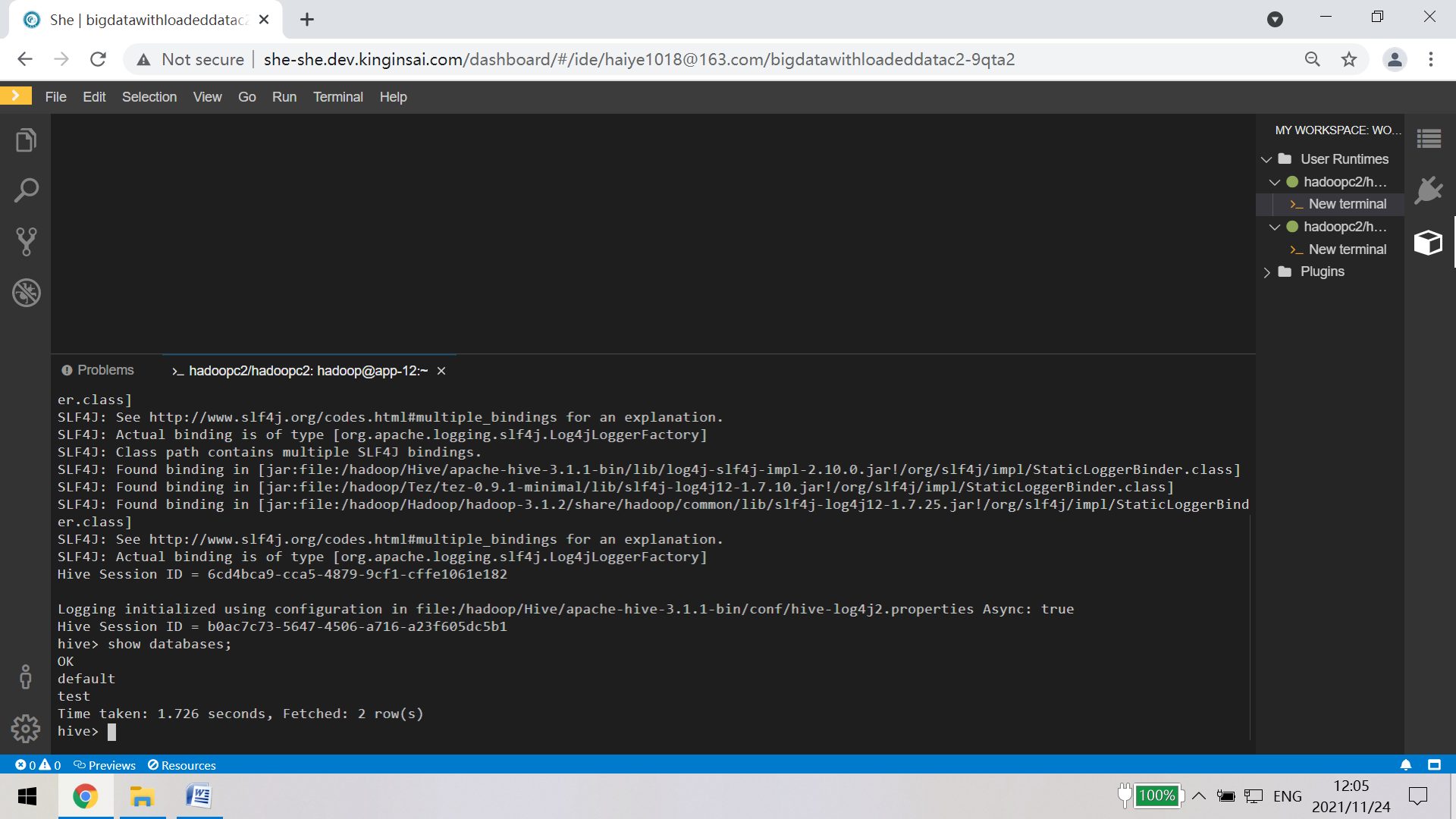
4. All In one的教研实训操作界面,快速高效的达成教研实训目标。以集成了所有大数据框架的全生态的BigDataWithLoadedData集群为例加以阐述。
创建BigDataWithLoadedDataC1、BigDataWithLoadedDataC2、BigDataWithLoadedDataC3 三个Workspace,

这三个逻辑节点组成三节点大数据集群,

BigDataWithLoadedDataC2集成Hive的操作界面,
BigDataWithLoadedDataC3集成Spark集群管理界面,

BigDataWithLoadedDataC1则集成了开发环境、源码环境、集群主控界面、内置浏览器、Flink集群管理界面等核心功能模块,
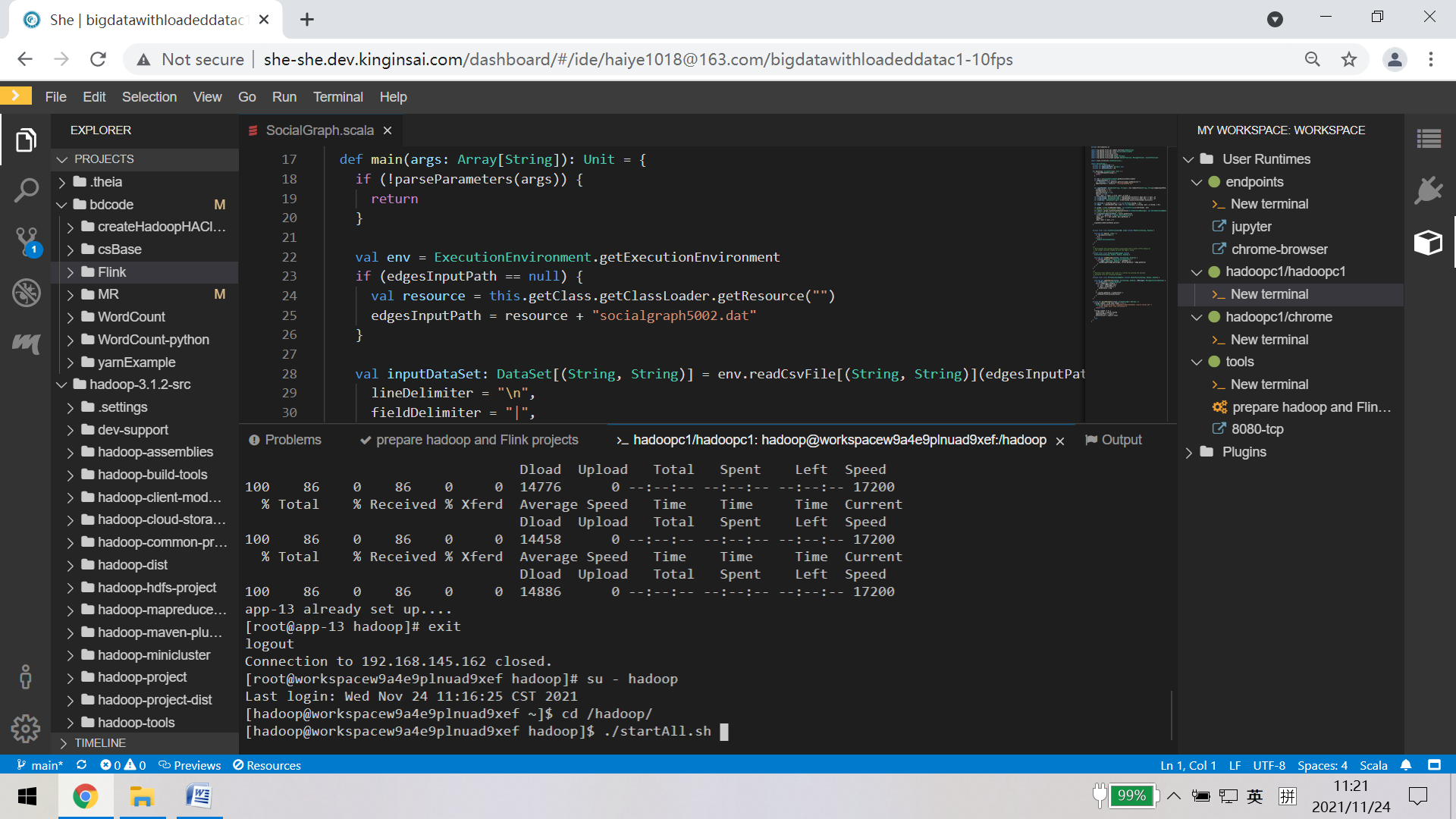
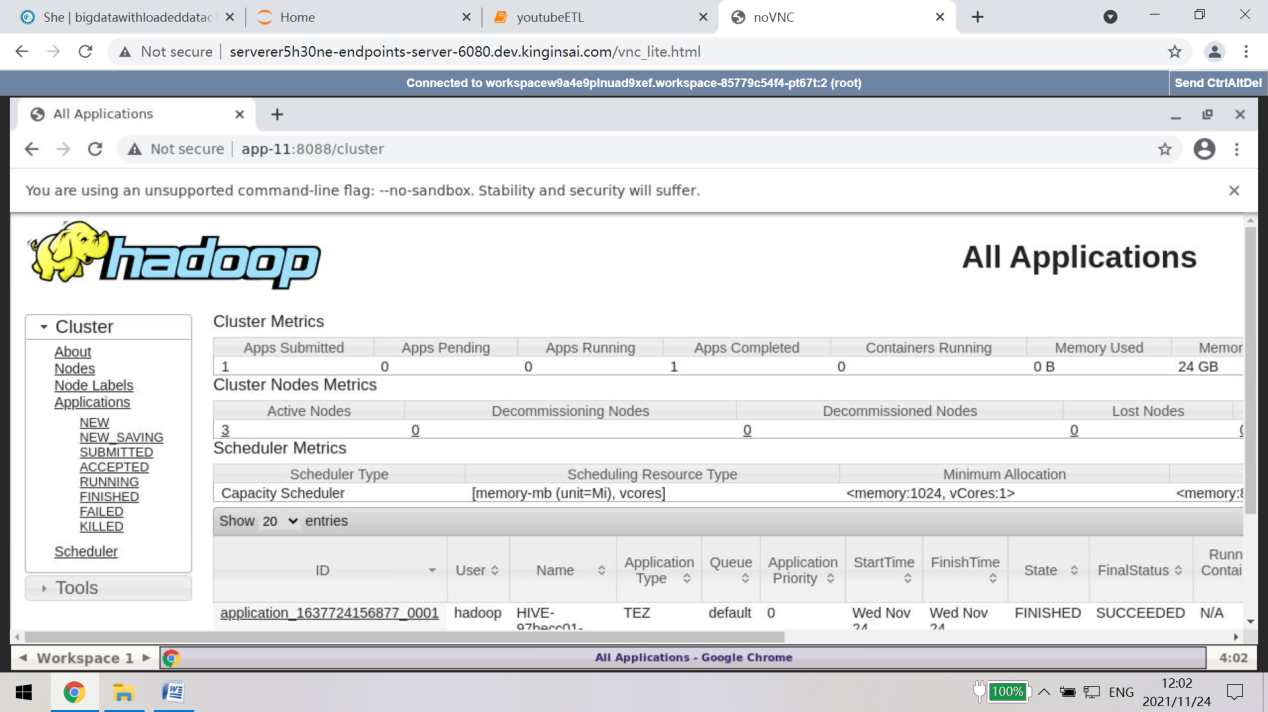
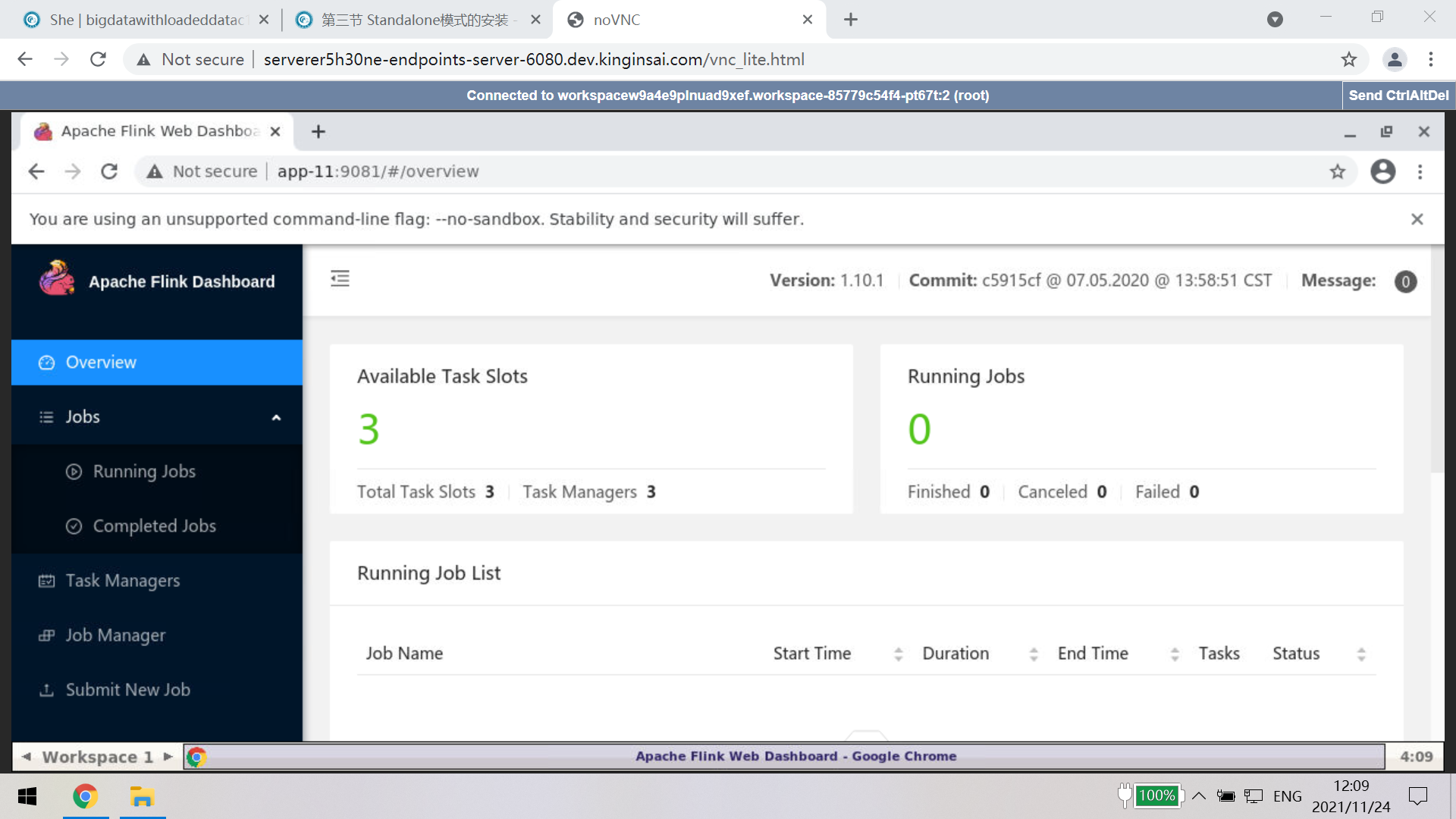
这种一体化的解决方案、可视化与命令行并重的教学实训方法论,适用于原理教学与应用教学,既适用于培养中高端大数据人才,也适用于培养应用型人才。
随着时代的发展,信息技术与商业活动交汇融合,企业产生了海量数据,大数据产业随之迅猛发展。根据世界经济论坛关于未来工作的报告,对数据分析师和数据科学家的需求增长最为迅速。“十四五”规划纲要将数字经济列为国家战略,推动数字产业发展、提升大数据应用水平也成为国家的发展战略。盖特纳咨询公司预测大数据将为全球带来440万个IT新岗位和上千万个非IT岗位。由于大数据的应用通常需要以深度的业务理解为依托,大数据+成为新型交叉学科,以计算机为基础、同时融合了管理学、哲学、经济学、社会学、法学、财税学等领域知识,这导致既熟悉业务需求又了解大数据技术与应用的人才缺口达150万,中国是人才大国,但能理解与应用大数据的创新人才更是稀缺资源。更高层次的目标则是培养具有国际视野、创新意识能力及领导潜质的高级管理人才,能够独立在商业、金融、制造等相关领域从事数据分析、商务智能决策、信息管理、业务流程优化等工作,从而为学生成为未来的业界领袖或学术大师奠定基础,而这类高层次人才缺口更大。
为此,She平台:
1. 引入开源BI工具Superset、结合人工智能AFS平台,为学生提供数据挖掘、数据建模与数据可视化实操环境。
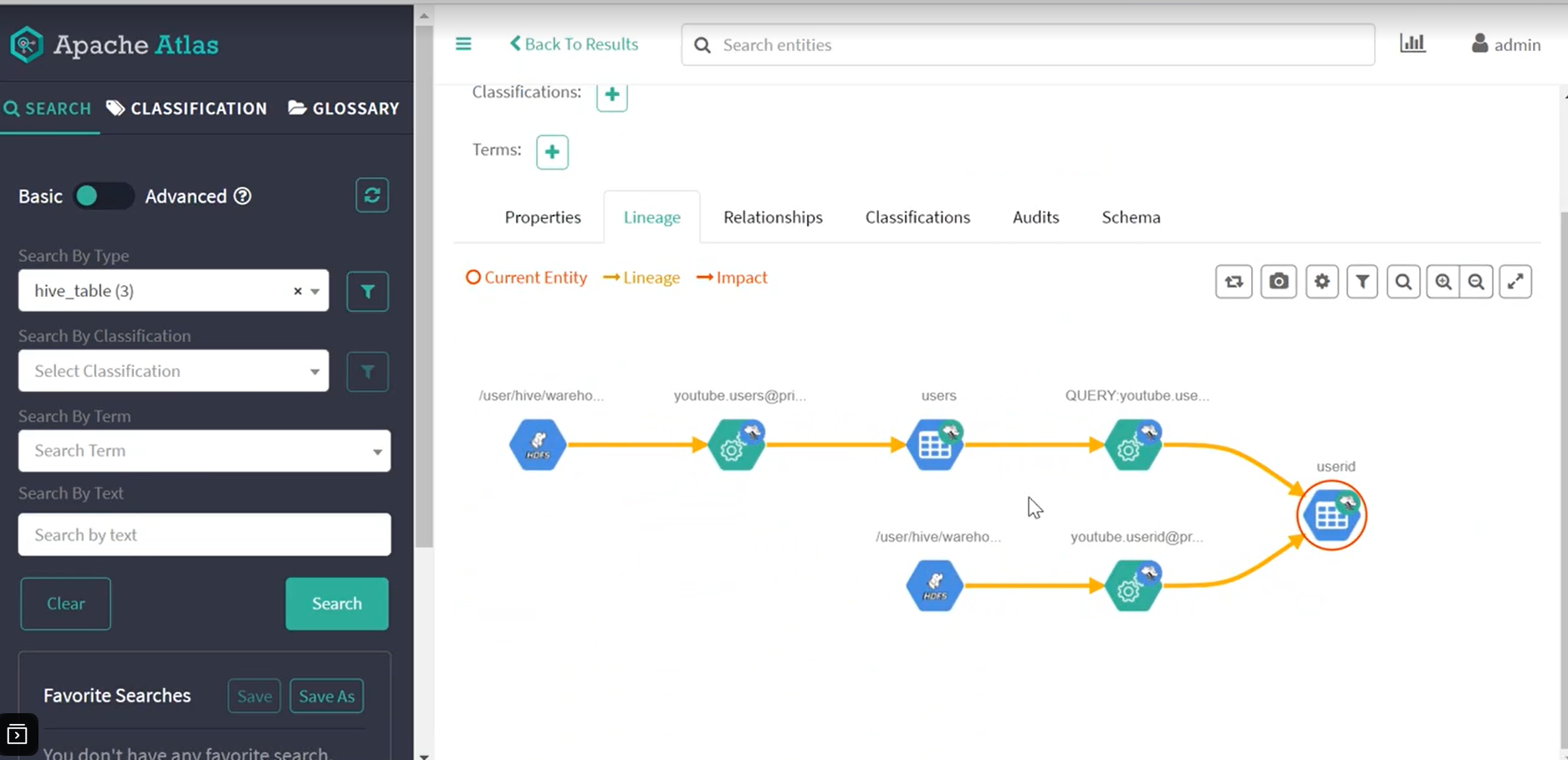
2. 引入Atlas数据血缘管理工具,为学生提供数据治理、大数据管理可视化实操环境。
3. 完备的数据仓库建模项目,为学生提供更深入数据分析实操实训一键式集成环境。此外,松耦合的架构,She平台可以根据大数据+学科的领域特点,便捷地加载相应大数据集;以便于学生高效地掌握大数据的基本理论、分析方法和管理技能。

4. 计算机、大数据、人工智能全套的课程体系,方便大数据+学科学生的快速学习计算机相关专业知识,潜移默化地提升理工科思维能力。
不同于大数据学科,人工智能的学习曲线异常陡峭,而且绝大部分情况下投入了巨大的学习精力却无法达到企业岗位要求,
1. 人工智能学科、特别是深度学习分支发展过快,state-of-the-art算法的论文刚刚发表,新的state-of-the-art算法就已经出现,学习者很难跟进这种快速变化,这极大的降低了学习效率。
2. 人工智能学科是实践性较强的学科,某个具体算法或方法通常只能解决某个特定的、应用领域较窄的问题,但常常这些算法被当成一种基础理论方法搬上课堂,给学生带来较大的误解,造成原创或应用型人才难以培养。
3. 人工智能基础原理学习往往被忽视,一方面,由于没有一种加速理解这类抽象概念的实验平台,而自己动手去将过于抽象的概念可视化展现存在巨大的门槛,特别是软件开发门槛,因为这个学科的学生通常不具备软件开发经验、特别是复杂软件系统开发经验;另一方面,不深刻领悟原理往往导致错误的判断,经常会遇到为全行业服务的通用模型平台类项目就是佐证。这种错误判断如果仅仅发生在工程师那里影响可能还不是特别严重,但如果业务管理决策者有此想法,造成巨大经济损失、错过发展机遇这类后果往往是致命的。为此,松鼠学苑原创AFS(AI From Scratch)平台用于人工智能学科教学实训。
本着为社会培养产业急需的人工智能人才、解决新兴科技人才短缺与产业人才分布不合理问题、服务于国家科技振兴大局的宗旨,发挥校企共建的互补优势,松鼠学苑在人工智能学科建设方面具备以下优势:
1. 虚拟化实操环境,降低学习门槛,减小学生设计操作错误的时间精力成本。融合CPU/GPU算力单元;集成大数据平台HFS,实现数据与算力的无缝连接;算力单元可编辑调控;资源按需申请,自由释放。这些优势特征保障每名学生的计算需求,提升了学生的学习效率,特别适用于原理教学。
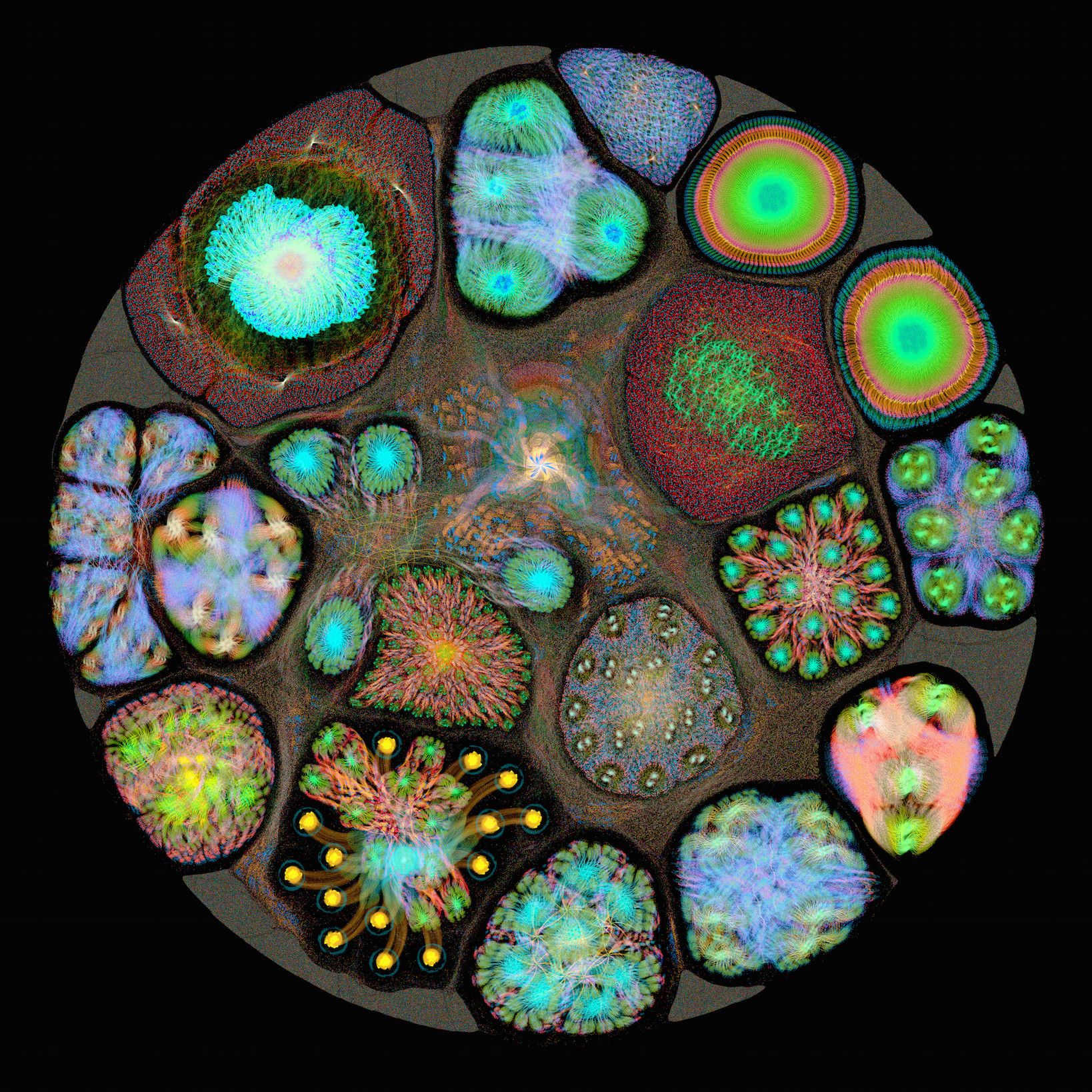
2. 原创的深度学习模型可视化组件,将过于抽象的深度学习理论三维展示,让学生可以感性认识深度学习模型每一个神经单元的实际变换效果,降低学生学习成本,提升教学水平。

3. All In one的教研实训操作界面,快速高效的达成教研实训目标。以Tensorflow开发集成环境为例加以阐述。
为减少因本学科实训项目的增减更新造成的AFS平台升级次数,内置了可视化项目和深度学习案例从git Repo下载功能,
不同风格的命令行环境,满足不同类型学生的使用习惯,
可360度观察的深度学习模型可视化工具,
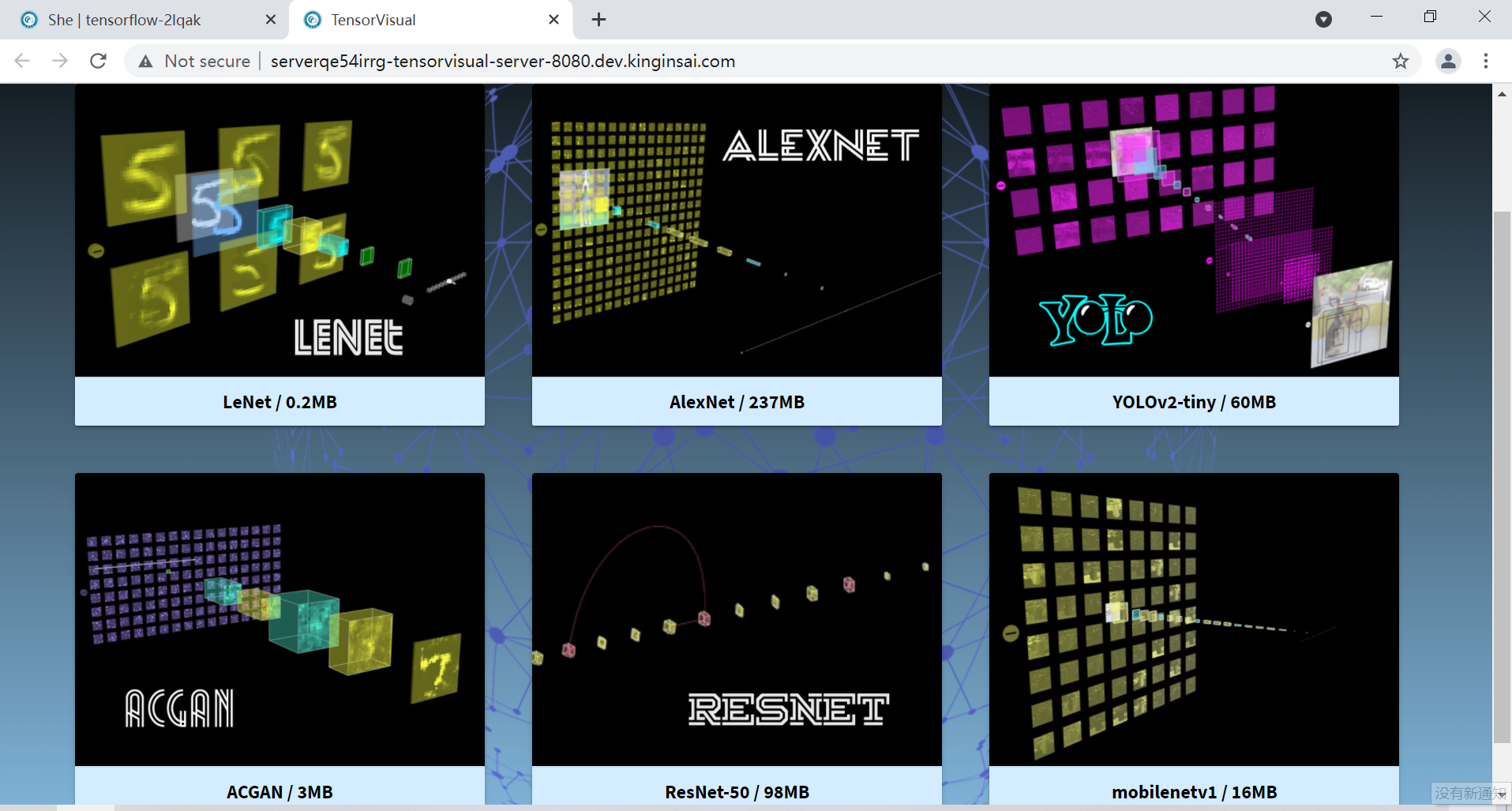
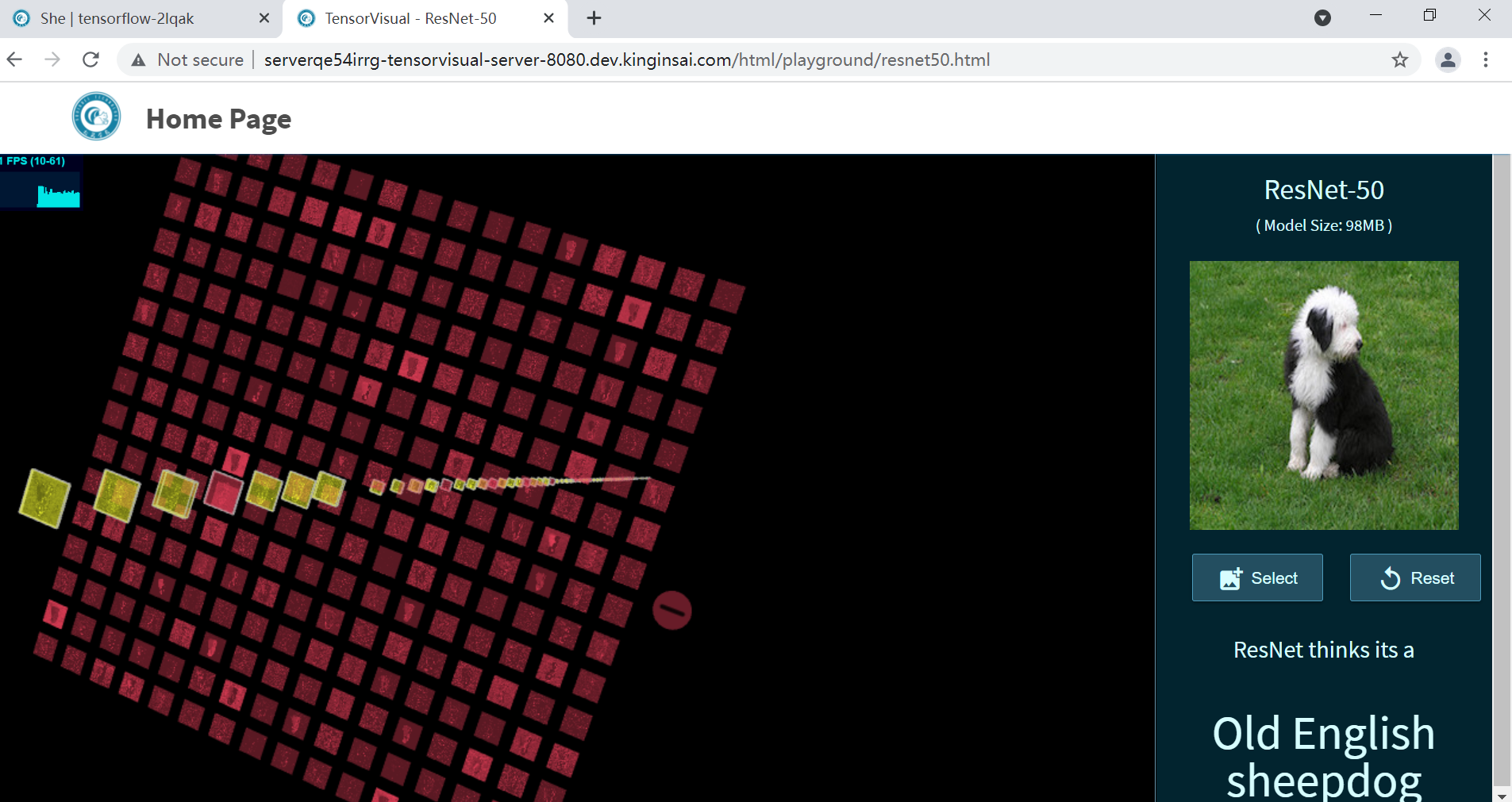
集成Tensorflow模型训练与预测可视化工具Tensorboard,以及与之相配套的启停预设命令,

这种一体化的解决方案、可随时集成变动实验项目的特性可降低人工智能学科、特别是深度学习分支发展过快给教学带来的冲击力。
网络空间安全学科的突出特点是实训操作往往具有破坏性,网络攻击的结果通常会导致靶机环境破坏、而网络防护的效果检验又需要网络攻击的配合,这同样会破坏靶机环境。此外,由于网络攻防的场景众多,很难有效的模拟出这些场景,这些困难增加了这个学科教研实训平台建设难度,
1. 理论派:基于某个成功操作结果,图文并茂的讲解网络攻击过程、防护策略、工具的应用,学生只能通过看图理解这些内容。
2. 密码学派:将网络攻防等同于密码学,学生无法接触到主流网络安全工具与网络攻防实践,枯燥的学习内容导致学生不愿继续深入学习,也很难学以致用。
3. 工具派:以攻防工具为核心内容,学生学习的是这些工具的操作,形成了一个不好的印象,即只要胆大心细,操作这些工具就能达到攻击的目标、而无需深入掌握这背后的原理,这种学科建设模式拉低了这个学科的建设高度。
为此,松鼠学苑研发NSP(Network Security Platform)平台用于网络安全教研实训。
本着为社会培养产业急需的网络安全人才、解决高端人才短缺问题、服务于国家安全大局的宗旨,发挥校企共建的互补优势,松鼠学苑在网络空间安全学科建设方面具备以下优势:
1. 以虚拟化技术和SDN(Software Defined Network)技术构建复杂网络场景,集成常见操作系统环境的靶机,学生不仅能直接观察到攻击的全过程,也能观察到特定防护措施的防护过程与实际效果,提升学习效率。
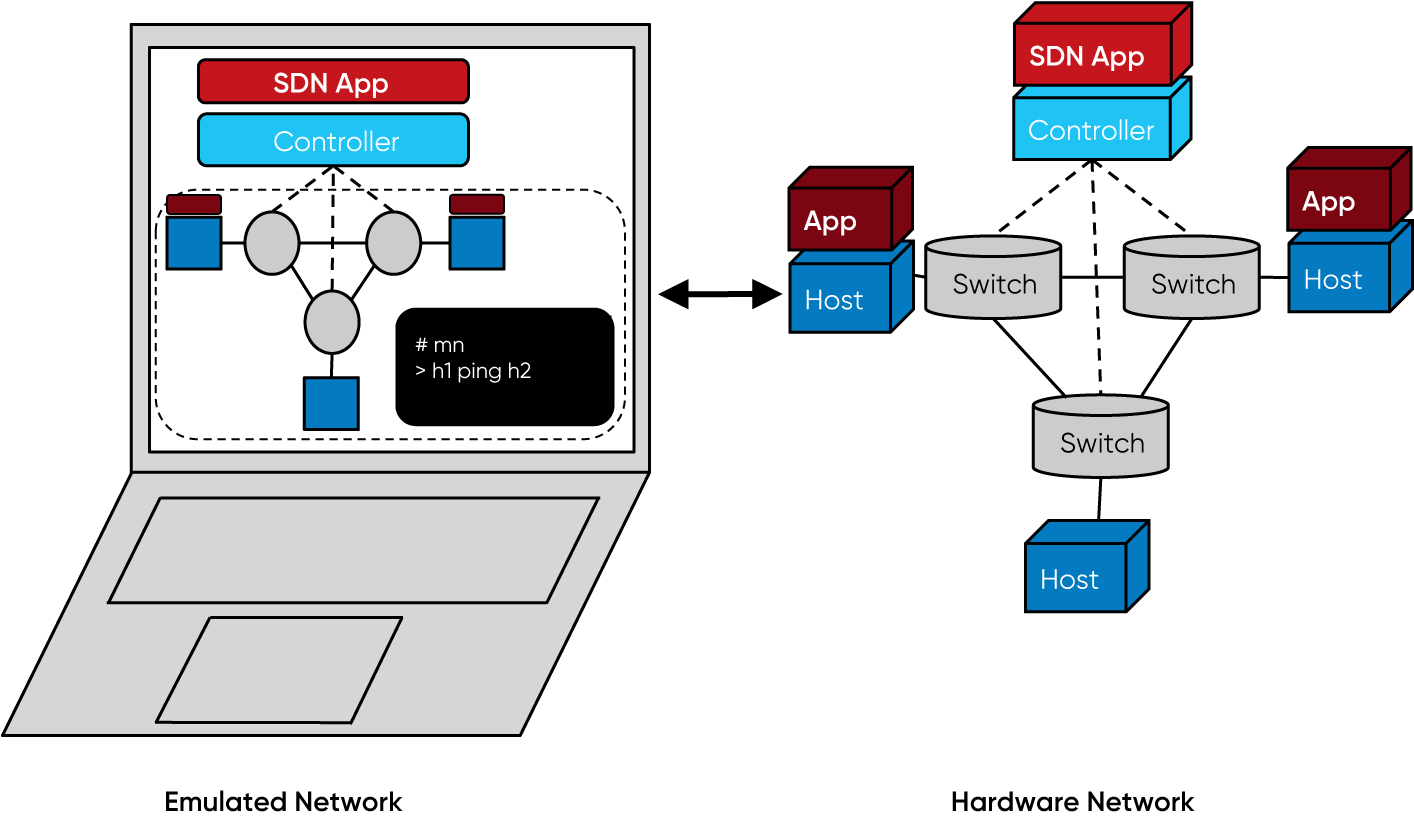
2. 集成主流的攻防工具,降低安装卸载这些工具的时间成本。可以随时创建随时删除已经破坏掉的环境,提升了学生的学习效率。
3. 实验环境隔离,即可配置网络安全学科环境与外界环境完全隔离,以规避网络攻击误操作对实验室之外环境的不良影响。
4. web应用安全实验易实施:基于She平台提供的软件开发教研支撑平台提供的主流语言编程环境,降低了开展web应用安全实验的前置门槛。
5. All In one的教研实训操作界面,快速高效的达成教研实训目标,以下展开阐述。

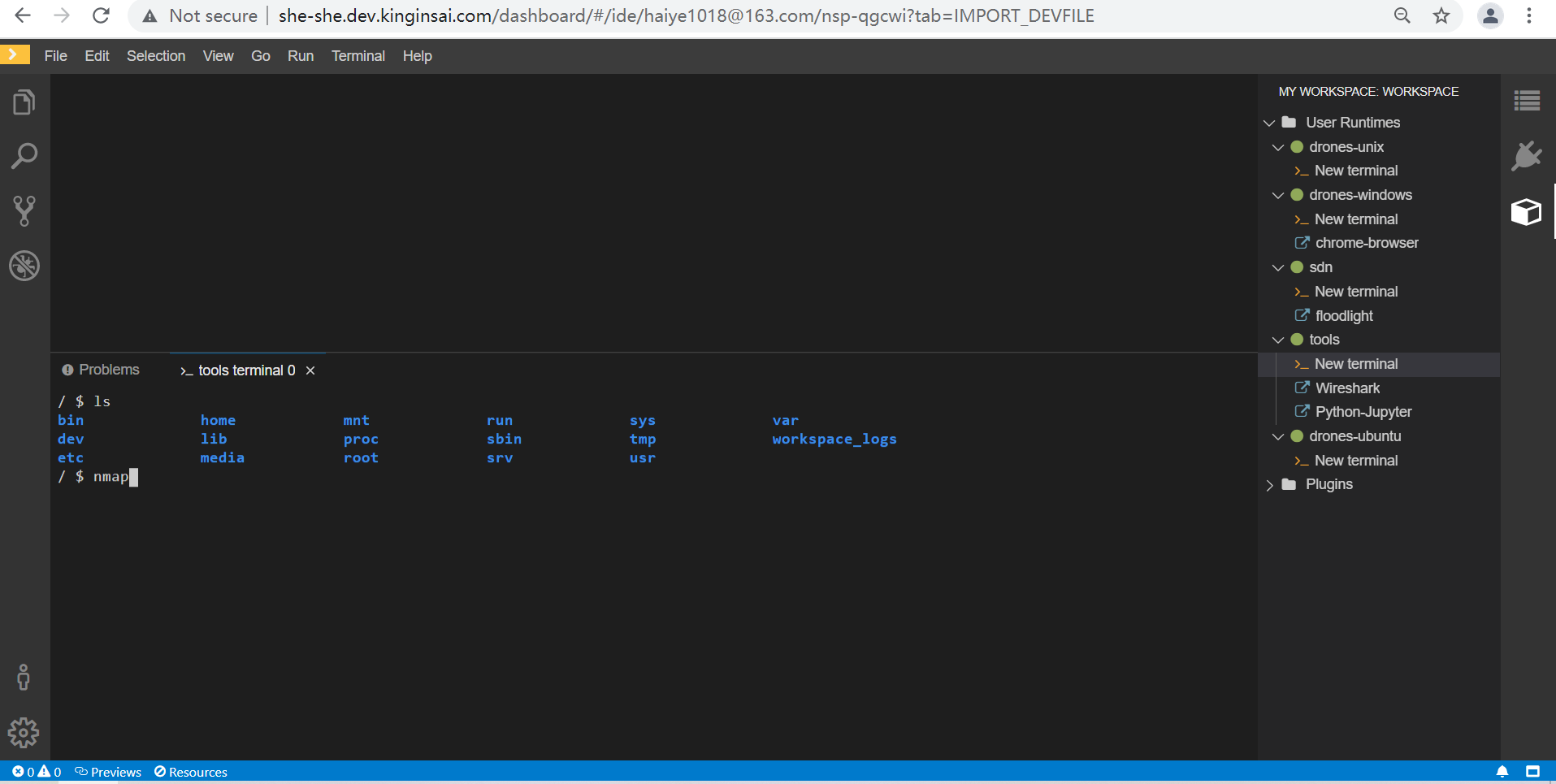
创建NSP Workspace完成后,主界面会出呈现工具容器、靶机容器、复杂网络拓扑结构容器,
其中,
工具容器集成各种网络攻防工具,如端口扫描工具nmap、OS指纹识别工具P0f、开源数据包分析器Wireshark等;软件开发工具,如gcc、gcc-g++、Python开发环境Jupyter;内部浏览器。
靶机容器则包括Ubuntu操作系统靶机、Windows操作系统靶机、Unix操作系统靶机,适用于不同场景下攻防演练实训。
复杂网络拓扑结构容器则集成SDN实验平台,
为了实施web应用安全攻防实验,NSP平台借助She平台的计算机与软件开发教研支撑平台提供的Web Springboot模块,创建一套运行在Linux平台之上的、集成关系型和NoSql数据库的Java Web系统,支持XSS(Cross-Site Scripting)、CSRF(Cross Site Request Forgery)、点击劫持、URL跳转漏洞、SQL注入、OS命令注入攻击的攻防演练。
可同时运行这个Workspace,这样学生可以通过安全渗透工具攻击Java Web系统,后者开启调试模式则可以直观的观察到整个攻击执行路径;通过Web化的DBAdmin工具,学生及时检测到数据库被攻击的情况及防护情况。
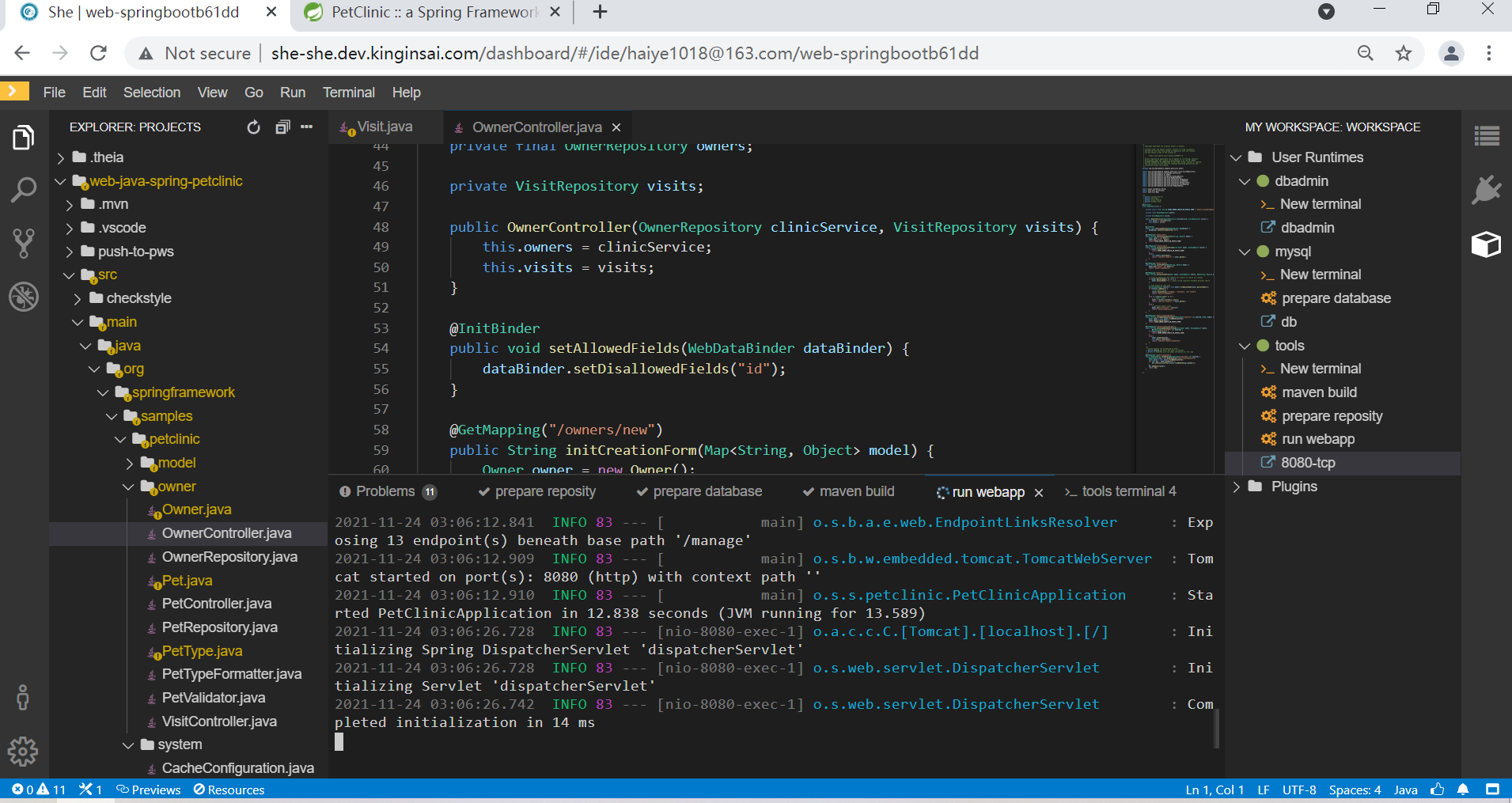
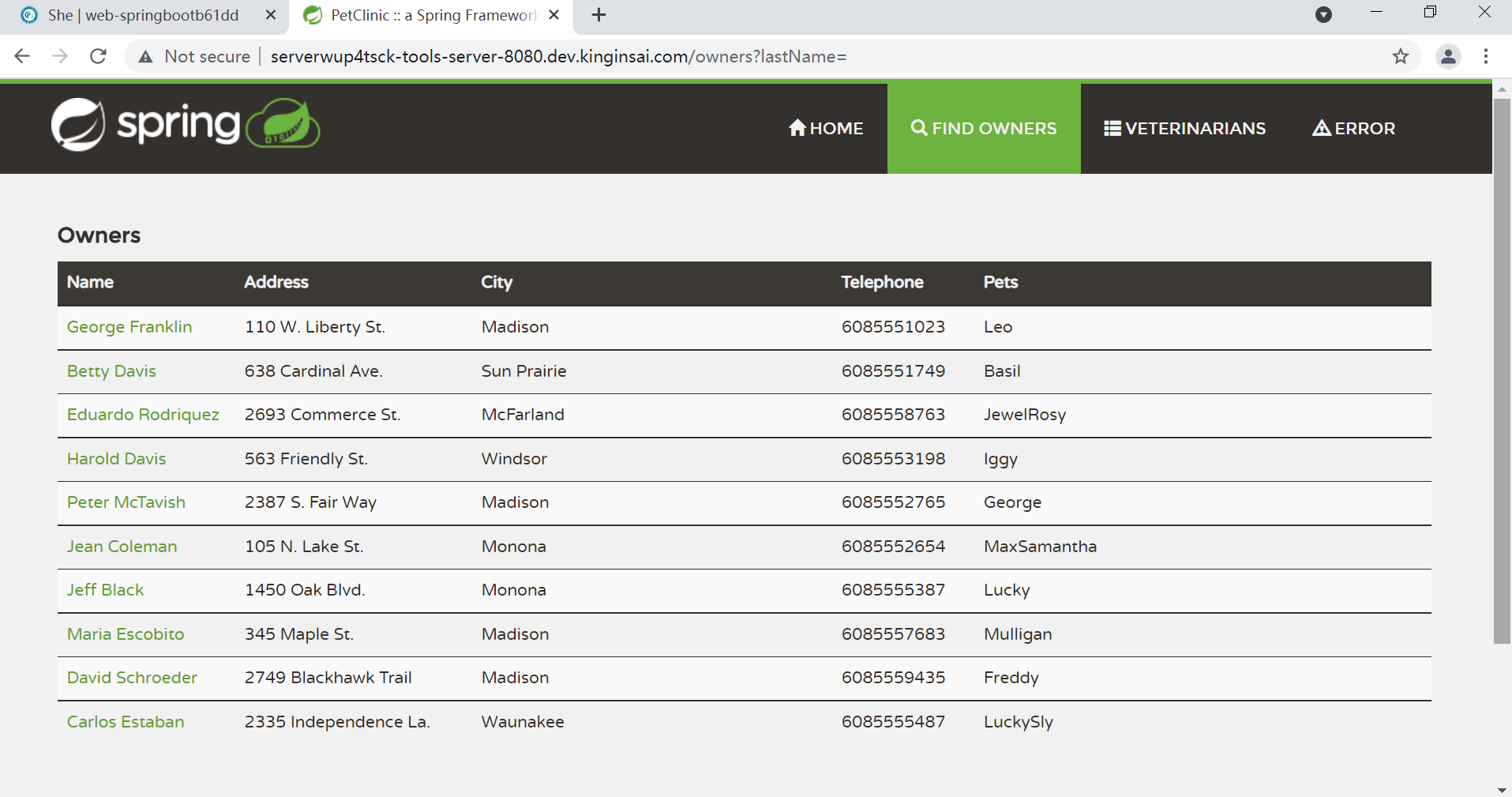
6. 集成移动端靶机环境。借助She平台的计算机与软件开发教研支撑平台提供的智能终端模块,学生可以创建一套Android开发环境以及支持ARM指令集的手机模拟器。
依托松鼠学苑的开放组织架构,天津精赛科技有限公司组建了一只强大的研发队伍。这只队伍用三年时间的打磨,完成She平台核心代码16000万行、周边代码68900万行、65个核心子系统、5篇核心设计方案、2篇深度研究报告,不仅支撑起She平台C端版本(She平台包括两个版本,C端版本部署在松鼠学苑的公有云上、面向相关领域从业者提供学习培训任务,高校版本通常部署在高校机房、为大中专院校提供学科教研实训)的高并发运行。快速响应能力、无缝升级能力、一键式部署能力、多种学习环境架构需求响应能力,都成为C端版本取得成功的核心因素。
在2021年上半年,松鼠学苑加大投入,为众多高等院校开放C端版本,解决了这些高校经费紧张的难题。在天津,与中国天津职业技能公共实训中心合作,松鼠学苑承担了天津市高校大四年级学生的计算机类学科实训任务。在云南和山东,松鼠学苑和12所高校开展大数据人工智能学科建设合作,She平台的强大功能和优秀的易用性取得了高校的一致认可。
以计算机学科培训和教研平台为主营业务,松鼠学苑积淀了丰富的计算机类学科建设和教学经验。截至2021年11月份,松鼠学苑共开展大数据集训营52期、 JavaEE集训营35期、NLP与深度学习集训营22期、大学生实训350期、高端企业培训12场、线下师资培训2期、线上师资培训10期。这些经验是松鼠学苑能够从容从事计算类学科建设的核心资产,也是松鼠学苑能够和体量庞大企业竞争的底气。
此外,借助于全球首创的大数据人工智能教研平台She,松鼠学苑解决了计算机类学科、特别是大数据人工智能学科教学实训的诸多痛点,这些经验和原创可以提升学科实验室的学术高度、打造专属的学科特色。
其次,松鼠学苑和众多知名企业建立了深度合作,借助于他们的能力为高校提供一站式校企合作服务:(1)、知名硬件服务器厂商,如联想、浪潮、戴尔、华为、中兴;(2)、知名互联网企业,如百度、阿里巴巴、腾讯、头条、58同城等;(3)、各行业知名企业,

最后,得力于天津市大数据人工智能产业的扩张,松鼠学苑获得了大数据协会的大力支持,这些支持让松鼠学苑站在新的高度去推动计算机类学科建设的发展,为国家培养高技能人才提供强有力的支撑。
随着互联网等新兴科技公司的市值飙升,码农以及关于码农的故事迅速进入大众的视野,相应地,软件开发这个行当也成为择业的热门选择之一。在我开始工作的那个时候使用一款叫SourceInsight的软件去编写C语言代码。这款软件体积很小,安装在程序员的本地计算机上,运行流畅,功能强大,
语法高亮(Syntax Highlighting)
自动格式化(Automatic Formatting)
自动补全(Autocomplete)
跳转到定义(Jump to Definition)
项目内查找引用(Find References in Project)
高级文本和符号搜索(Advanced Text and Symbol Search)
等等,这些功能是这款软件的标配。有了这款软件编辑工具,就可以开发出大型软件工程,然后将这个工程上传到Linux开发机,写MakeFile去编译生成可执行文件,当然这款软件也支持外部模块,如语法检查(Lint)工具。与此同时,Java语言正如火如荼地攻城掠地,而基于微软的Visual Studio,如C++、.Net等的地盘逐渐被蚕食;印证这种趋势的是,各地Java培训班办的风生水起,成为当时的蓝海。印象最深刻的是,当时我有一做美工的朋友竟然会大几千(那时的几千是值钱的)学习Java,徜徉在SourceInsight之美之中的我还很疑惑这个怎么这么值钱。
与之相对应的是,Eclipse迅速成为软件工程师(那时还没有码农这个词)的标准IDE,特别在做上层应用开发时。松鼠学苑的Devfile和Workspace概念就是从这条主线发展而来。
但是,当软件系统越来越庞大时,如微服务系统,则需要安装的工具也越来越多,外部依赖的环境也越来越复杂,单机已经不能开展软件开发调试工作。相应地,环境的一致性也成为码农最头疼的主要问题之一:A开发的代码在B的环境下不能正常工作,尽管A在自己的环境测试没有问题;由于系统的复杂性,需要准备一系列类似于生产的环境用于开发,这又导致软件工程师需要自己搭建一套准生产环境,但是受限于资源,这个准生产环境往往是生产环境的阉割版、而且由于不能在软件工程师本机上完成这个准生产环境的搭建而导致这种用于开发测试的环境也不能人手一份,这又徒增了码农的烦恼。
编程语言在发展,IDE工具也在跟进。
基于协同开发的考虑,网络IDE是一个选择,因此产生了一批批做在线IDE的公司。
编程语言是丰富的,而同一个软件项目也不一定选择一种编程语言、一种框架,这要求软件工程师需要安装多种IDE,如前述的Eclipse、IDEA、PyCharm、JetBrains、Komodo、Sublime、古老的Vim等等,这种放羊式的粗放发展也是软件工程师的噩梦。于是乎,All In One成为救命稻草,在这种背景下,语言模型LSP(非人工智能领域的自然语言中的语言模型)架构了这种全新的IDE,而历史又绕回了微软:开源了其单机版的Visual Code,编程的各种标配功能,如语法检查与补全,成为这款软件的核心功能;LSP模型也让其能够处理各种编程语言的软件项目开发。
正是有了上述的技术铺垫,基于浏览器的IDE应运而生,有了Visual Code的微软很自然地开发出了相应的网络IDE;为适配国内的开发实际,特别是大数据、人工智能的开发实际,松鼠学苑开发出She软件开发云计算平台。
有了上面的梳理,关于Devfile和Workspace的概念便不难理解了。如果要做一个电商系统,则需要分布式数据库软件、需要各个微服务的子系统、需要一个能够编写调试的IDE、需要一些辅助工具集,那么最好的办法是将这些服务和工具安装在一个个容器上形成一个与生产环境相同拓扑结构的准生产环境;为了支持这个环境的随时一致的搭建,将这个环境的拓扑结构画在一张独立于语言的稿纸上,而这个稿纸就被定义为Devfile、独立于语言的实现方式是带格式文本如yaml。
如果说Devfile是草稿,是静态的,那么将这个草稿建设起来的就是Workspace,即Workspace是物理的、而Devfile是逻辑:Workspace包括了物理上运行的各容器或物理机实体、端口、命名等一干看得见摸得着的资源。
使用场景说明:
She平台C端版本承担师资技术交流和相关职业类培训业务,例如,高校教师参加松鼠学苑主办的线上或线下大数据与人工智能方向师资技术交流班,那么这里的高校教师不需要通过微信付费购买的方式使用平台、而是申请免费授权使用。
对于部署在高校侧的She平台,后台管理员创建班级、在校学生通过申请免费授权使用的方式使用She平台。
以上高校教师和在校学生均定义为She平台用户,以下是申请免费授权使用的操作流程。
1. 登录She平台,点击My Acount进入用户后台

2. 在用户后台界面中点击APPLY FOR FREE按钮,进入申请免费授权使用页面

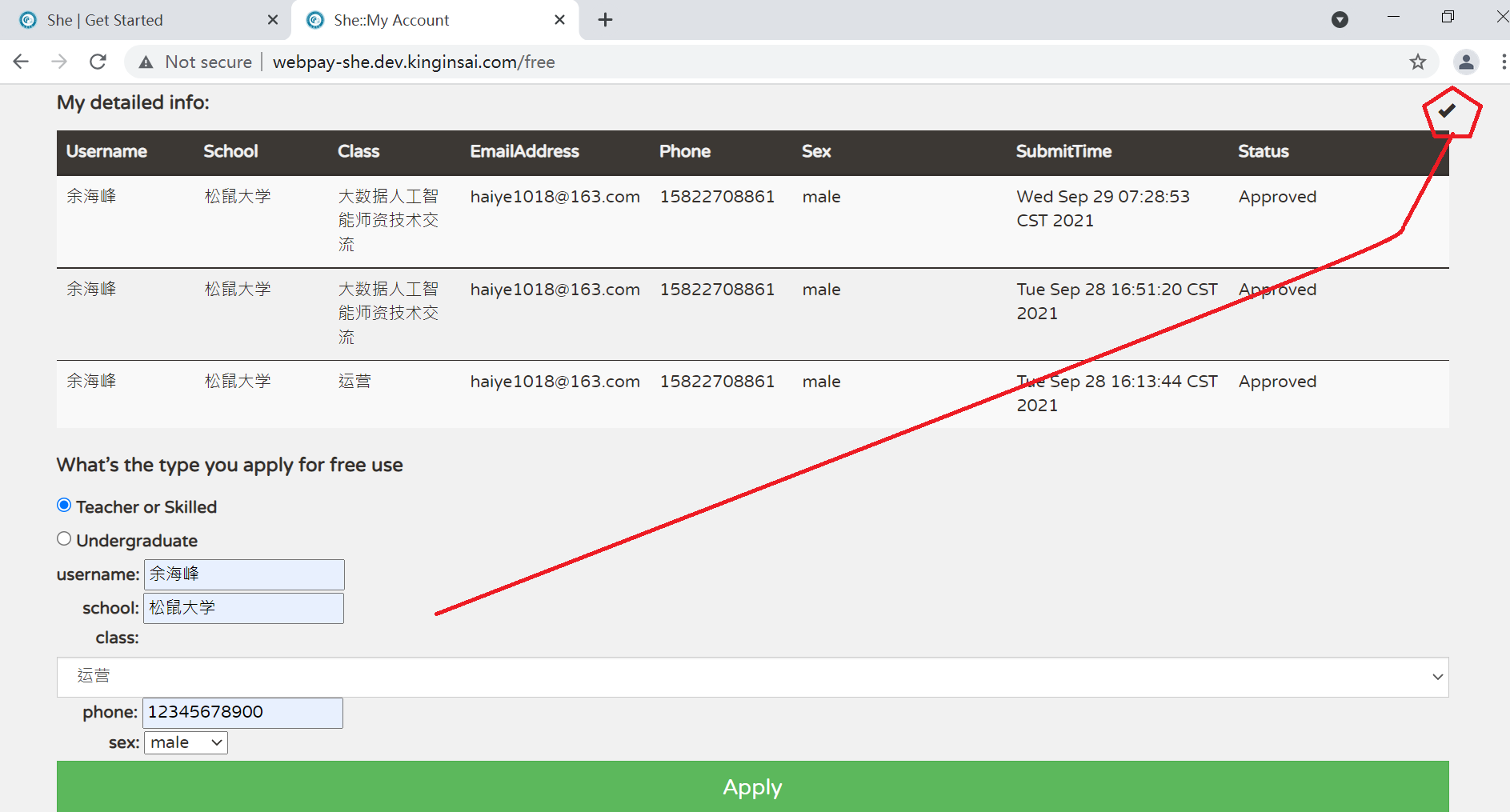
这个页面中包括三个区域,其中
位置1所指示区域是授权成功信息,申请没有被Approved、或者授权到期解除则这个区域为空。
位置2所指示的区域是授权提交及审核情况,审核包括Approved、Waiting for approval两种状态。
位置3所指示的区域是提交新的申请区域。当已经被授权免费使用(即区域1不为空)、或者之前提交的申请处于Waiting for approval状态,则此区域不存在(即不允许提交新的授权申请)。
3. 提交申请
完整填写自己的信息然后点击Apply则完成申请的提交。
(1). 当填写信息不满足相应规则时,Apply按钮失效;当填写信息满足规则且所有输入均填入,则在页面的右上角会出现对勾。
(2). 对于高校教师参加松鼠学苑主办的线上或线下大数据与人工智能方向师资技术交流班单选”Teacher or Skilled”;对于高校版本,在校学生则单选”Undergraduate”。
(3). class为下拉选择,高校版本由后台管理员创建好班级信息;对于高校教师参加松鼠学苑主办的线上或线下大数据与人工智能方向师资技术交流班、则选择”大数据人工智能师资技术交流”。
提交完成后,界面如下,
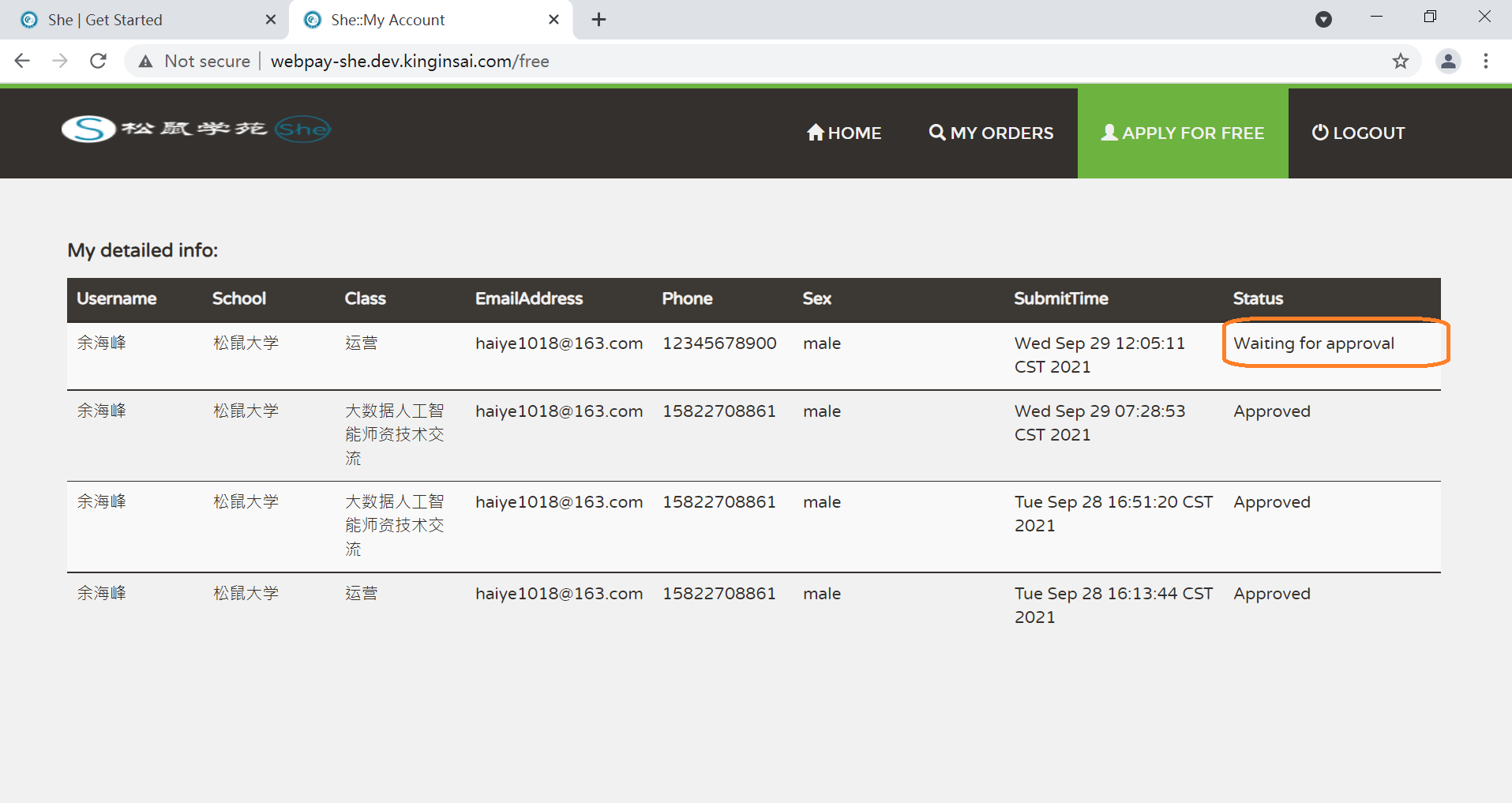
4. 申请被Approved的界面

1. 登录She平台,点击My Acount进入管理员后台
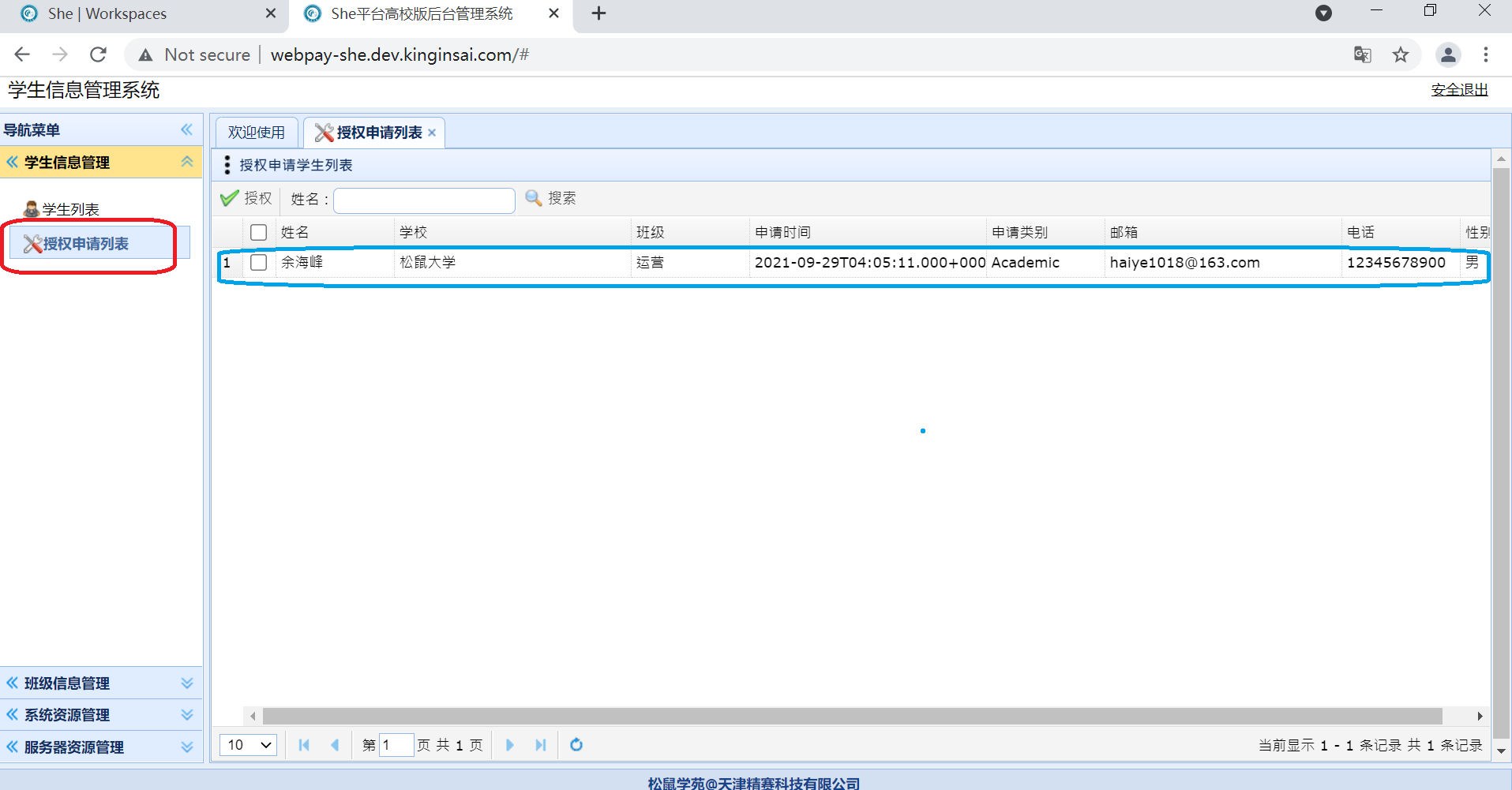
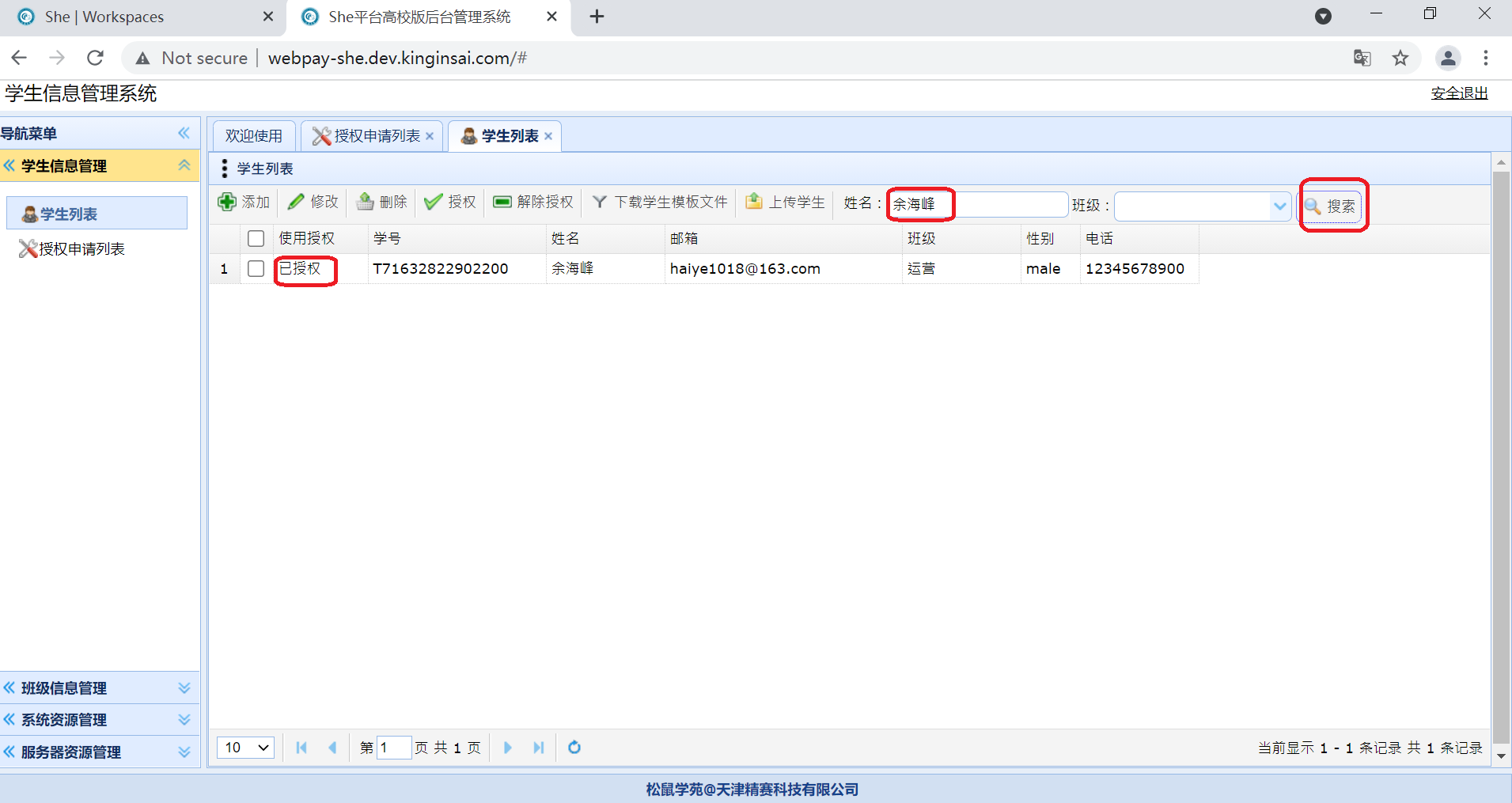
授权成功后,在学生列表页面中可以查看授权状态,
1.She不是类似于学习通、智慧树等教学平台,She是用于大数据人工智能等学科教研和实训的平台,可以通俗的称之为云端实验室。
2.She属于全球首创、专门用于高等学校大数据人工智能等学科教研和实训的平台,是基于产业界专利成果、培训实践成果总结和高等学校教学实践研制而成,是复杂度较高学科、如大数据人工智能,教研实训必不可少的平台。
3.创新在线IDE理念,She平台不需要学生在本地计算机安装额外软件,而只需要浏览器即可开展全部实训。
4.She是架构灵活的开放式平台,可快速无缝集成其他教研实训子系统,如类似学习通的教学组件、类似GitHub的GitRepo以便于学生编写代码的实时自动存储、类似于Coursera的在线课程平台,这些都是内置可定制组件,其中在线课程平台采用电子书的方式集合教学视频和电子教材,方便学生实训学习。
我们的系统之所以采用英文界面,是因为涉及到大数据、人工智能、软件开发领域的词语大都来源于欧美以及以英语为官方语言的开源社区,如果我们生硬地将这些业内从业者所熟悉的词汇和表达转换成中文,则一者这种转换很难用较短的词汇表达的那么清晰(因为页面上用词都是短词汇)、二者也无法让我们平台的学员用户快速融入这个软科学领域。
大数据是数据量爆炸式增长时代的软件基础设施、人工智能则是大数据时代的数据价值挖掘利器,所以从这个意义上讲,大数据人工智能仍属于计算机软件,但是大数据人工智能的持续热度是有目共睹的,而且大数据人工智能的方法论对产业界及社会发展的推动作用也是巨大的。因此,很多高校都争相开设大数据人工智能专业、或者开设相关课程。
但是,也会有高校老师对此提出疑问:大数据专业的就业岗位有那么多么?是大数据专业的就业岗位多还是传统的Java开发岗位多?我们学校是高职学校、三本院校,如开设人工智能专业学生能学会吗?
首先,大数据人工智能是大数据时代的软件开发方法论,具体的,大数据是海量数据下软件基础设施建设方法论、人工智能是非显式编程的方法论。不同于某一门具体编程语言或框架,方法论不会轻易过时,而是随着技术的发展会成为基础学科,就如同C语言一样。而且,这种方法论,反过来会变革传统计算机和电子信息类学科。
其次,从就业的角度上看,大数据中的很多内容是诸如Java开发岗位必须具备的;Java仅仅是一门编程语言,从业者如果想从事Java开发也需要更多专业知识的支撑,因此,有大数据专业背景的Java开发人员会更具市场竞争力。人工智能学科也是如此。
从产业划分来看,我们的社会只有三种企业角色:
1.负责国计民生的国有企业,如国企、央企。
2.负责构建并维护领域内的基础设施的平台企业,如社交之于腾讯、电商之于阿里和京东、搜索引擎之于百度。
3.在各种细分领域里有独特产品或深度服务的中小企业,这类企业深耕一个小的领域、提供最优质的定制化服务。
所以说,选择其他领域巨头公司的优势是显而易见的,但是其基因决定其不可能为一个小的市场提供诸如电信产品那样强大的技术服务,而教研平台的本质是就是服务,只有我们这类企业才能俯下身做好这类定制化服务。
首先大数据人工智能的浪潮也是最近几年的事,而大数据人工智能进入高校的时间更短,所以从这个角度分析,如果说某家公司号称有很多年的大数据人工智能教研经验、这很显然只是一种不负责任的宣传口号而已;这其中更多的是快速的市场淘金,但教书育人通常是润物细无声、潜移默化,我们的教材教案教具是需要长期打磨不断迭代的,而这通常需要一个过程。根据我们的市场调研,市场上通常采用工业级大集群、虚拟机、单机版的虚拟桌面等方案,这些都是快速复制产业界的产物,不能满足学生这个特定群体的实训需求,如学生不能快速恢复某个错误之前的状态、不能独享一套集群环境等。
其次,我们在2016年便开始联合就职于百度、阿里、华为、头条、新浪、58同城等一二线互联网企业以及大型金融机构的资深大数据人工智能高T组建了松鼠学苑,当时的目标是推广前沿科技以加快我国的软件科技发展,这期间我们承接高端定制化培训,这让我们深刻理解学习大数据人工智能的诸多痛点,也坚定了我们研发She平台的决心;所以,从这个意义上讲,我们是真真正正在做大数据人工智能教研攻坚,投入了巨大的人力和资金。
方案1:购买终身使用权:我们会根据学校的硬件资源情况,选择部署在基于自建机房的集群上、学校自有的私有云环境、学校购置的公有云上,由我们提供运维服务。当学校暂无硬件环境时,我们可以根据学校的实训科目与并行实训学生的人数,额外采购硬件一并与She平台打包提供给学校;免费定制课程、3年内免费运维与升级。
方案2:软件授权使用模式:学校已有足够的服务器硬件资源,且该专业教学模式处于探索阶段,我们将She平台部署在学校内、并提供相应课程。这种购买方式一次性投入费用相对较低、且学生可通过校内网访问,访问效果好,且可随时终止试用。
方案3:购买松鼠学苑C端版本账号模式,这种模式不需要学校有任何前期投入。